“Apache Spark, Spark SQL, DataFrame, Dataset”
Apache Spark is a cluster computing system.
To start a Spark’s interactive shell:
./bin/spark-shell
Dataset is a a distributed collection of data. It is a strongly-typed object dictated by a case class you define or specify. It provides an API to transform domain objects or perform regular or aggregated functions. In our script below, we create a dataset of lines from a file. We make action call to count the number of lines and to retrive the first line. We transform the dataset with filter to another dataset of lines that containing the word “Spark”.
scala> val textFile = spark.read.textFile("README.md") // Create a Dataset of lines from a file
scala> textFile.count() // Perform an action on a dataset: return 126 lines
scala> textFile.first() // First item in the Dataset
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark")) // Transform to a Dataset of lines containing "Spark"
scala> textFile.filter(line => line.contains("Spark")).count() // Count
More examples for dataset transformation: flatMap transforms a dataset of lines to words. We combine groupByKey and count to compute the word-counts as a dataset of (String, Long) pairs.
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) // Map returns a new Dataset of words
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count() // Dataset of lines to a Dataset of word-counts
scala> wordCounts.collect()
We can make other function calls inside the chain of calls:
scala> import java.lang.Math
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
Caching
Spark supports pulling datasets into a cluster-wide in-memory cache which can be accessed repeatedly and effectively. This is good for hot datapoint that require frequent access.
scala> linesWithSpark.cache()
scala> linesWithSpark.count()
spark.catalog.cacheTable(“tableName”)
Self-Contained Applications
We will walk through an example to build a self-contained application. The following is an application to calculate the value of \(\pi\).. We create a square with width 2 which embeds a circle with radius 1. We generate many parallelized threads to create random points inside the square. The chance that the point is within the circle is:
\[count \approx \text{number of tries} \cdot \frac{\pi r^2}{ 2r * 2r} = (n-1) \frac{\pi}{ 4}\]In our application, we count the number of times that it is within the circle, and use the formula above to count \(\pi\).
package org.apache.spark.examples
import scala.math.random
import org.apache.spark.sql.SparkSession
/** Computes an approximation to pi */
object SparkPi {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / (n - 1))
spark.stop()
}
}
Building a Spark application
sbt is a build tool for scala applications. Our sbt configuration file build.sbt declares our application depends on Spark.
name := "SparkPi Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.2.0"
We build a directory structure for the application and use sbt to build and package the application.
# Directory layout
$ find .
.
./build.sbt
./src
./src/main
./src/main/scala
./src/main/scala/Pi.scala
# Package a jar containing your application
$ sbt package
...
[info] Packaging {..}/{..}/target/scala-2.11/sparkpi-project_2.11-1.0.jar
Running a Spark application
We submit a Spark application to run locally or on a Spark cluster.
# Use spark-submit to run your application
$ YOUR_SPARK_HOME/bin/spark-submit \
--class "SparkPi" \
--master local[4] \
target/scala-2.11/sparkpi-project_2.11-1.0.jar
...
master is a Spark, Mesos or YARN cluster URL, or local to run the application in local machine. The following run a Spark application locally using 4 threads.
--master local[4] \
Spark SQL
Spark SQL is a Spark module for structured data processing. Spark SQL provides Spark with the structure of the data and the computation for SQL like operations.
Main function of a Spark SQL application:
object SparkSQLExample {
// $example on:create_ds$
case class Person(name: String, age: Long)
// $example off:create_ds$
def main(args: Array[String]) {
// $example on:init_session$
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// Spark built-in for object conversions
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
// $example off:init_session$
runBasicDataFrameExample(spark)
runDatasetCreationExample(spark)
runInferSchemaExample(spark)
runProgrammaticSchemaExample(spark)
spark.stop()
}
Create a Spark Session
We create a Spark session which later read data into a DataFrame.
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
runBasicDataFrameExample(spark)
Create a DataFrame
We create a DataFrame with a Spark session:
private def runBasicDataFrameExample(spark: SparkSession): Unit = {
// $example on:create_df$
val df = spark.read.json("examples/src/main/resources/people.json")
people.json file will provide the names of the columns as well as their values:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
A DataFrame is a Dataset organized into named columns. We address data field by name. For example, we can filter DataFrame by the column age.
df.filter($"age" > 21).show()
Display the content of the DataFrame
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:create_df$
Untyped Dataset Operations (aka DataFrame Operations)
We can use SQL like operation to manipulate the DataFrame:
// $example on:untyped_ops$
// This import is needed to use the $-notation
import spark.implicits._
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
// $example off:untyped_ops$
}
SQL temporary view
Create a temporary view on the data and use SparkSession’s sql function to run SQL queries and return the result as a DataFrame. Temporary view is scooped at session level. When a session is terminated, the temporary view will disappear.
// $example on:run_sql$
// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:run_sql$
// $example on:global_temp_view$
// Register the DataFrame as a global temporary view
Global temporary view
Global temporary view lives share among all sessions and terminate if the Spark application is terminated.
df.createGlobalTempView("people")
// Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:global_temp_view$
The full source code is available at [github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala]
Caching
Table can be cached to improve performance.
df.createOrReplaceTempView("people")
spark.catalog.cacheTable("people")
Dataset
Dataset is a strongly typed data structure dictated by a case class. The case class allows Spark to generate decoder dynamically so Spark does not need to deserialize objects for filtering, sorting and hashing operation. This optimization improves performance over RDD that is used in older version of Spark.
case class Person(name: String, age: Long)
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
private def runDatasetCreationExample(spark: SparkSession): Unit = {
import spark.implicits._
// $example on:create_ds$
// Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:create_ds$
}
Unlike DataFrame which access data by name, Dataset use the case class to access data:
peopleDS.filter(x=> x.age>21).show()
Inferring the Schema Using Reflection
Spark SQL can convert an RDD with case classes to a DataFrame.
We will create a RDD from the data file people.txt
Michael, 29
Andy, 30
Justin, 19
We use a case class to convert it to a DataFrame.
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
The case class defines the table’s schema. The arguments of the case class (name. age) become the names of the columns’ name for the Untyped Dataset Operations. Case classes can be nested or contain complex types such as Seqs or Arrays.
private def runInferSchemaExample(spark: SparkSession): Unit = {
// $example on:schema_inferring$
// For implicit conversions from RDDs to DataFrames
import spark.implicits._
// Create an RDD of Person objects from a text file, convert it to a Dataframe
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by Spark
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// The columns of a row in the result can be accessed by field index
teenagersDF.map(teenager => "Name: " + teenager(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// or by field name
teenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// No pre-defined encoders for Dataset[Map[K,V]], define explicitly
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
// Primitive types and case classes can be also defined as
// implicit val stringIntMapEncoder: Encoder[Map[String, Any]] = ExpressionEncoder()
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]
teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect()
// Array(Map("name" -> "Justin", "age" -> 19))
// $example off:schema_inferring$
}
Specifying the schema programmatically
A DataFrame can be created programmatically:
- Create a RDD of Rows from the original RDD;
- Create the schema with a StructType matching the structure of Rows in the RDD.
- Apply createDataFrame to create the DataFrame
private def runProgrammaticSchemaExample(spark: SparkSession): Unit = {
import spark.implicits._
// $example on:programmatic_schema$
// Create an RDD
val peopleRDD = spark.sparkContext.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a string
val schemaString = "name age"
// Generate the schema based on the string of schema
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// Convert records of the RDD (people) to Rows
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// Apply the schema to the RDD
val peopleDF = spark.createDataFrame(rowRDD, schema)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL can be run over a temporary view created using DataFrames
val results = spark.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations
// The columns of a row in the result can be accessed by field index or by field name
results.map(attributes => "Name: " + attributes(0)).show()
// +-------------+
// | value|
// +-------------+
// |Name: Michael|
// | Name: Andy|
// | Name: Justin|
// +-------------+
// $example off:programmatic_schema$
}
Aggregation
Spark provides built-in aggregation functions: count(), countDistinct(), avg(), max(), min().
Untyped User-Defined Aggregate Functions
We can also built custom aggregation functions. MyAverage provides an average salary of the following DataFrame.
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object MyAverage extends UserDefinedAggregateFunction {
// Data types of input arguments of this aggregate function
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// Data types of values in the aggregation buffer
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// The data type of the returned value
def dataType: DataType = DoubleType
// Whether this function always returns the same output on the identical input
def deterministic: Boolean = true
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Calculates the final result
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
// Register the function to access it
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("examples/src/main/resources/employees.json")
df.createOrReplaceTempView("employees")
df.show()
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
val result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show()
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
Type-Safe User-Defined Aggregate Functions
Custom aggregate functions for Dataset:
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Encoders
import org.apache.spark.sql.SparkSession
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Merge two intermediate values
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Transform the output of the reduction
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// Specifies the Encoder for the intermediate value type
def bufferEncoder: Encoder[Average] = Encoders.product
// Specifies the Encoder for the final output value type
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
val ds = spark.read.json("examples/src/main/resources/employees.json").as[Employee]
ds.show()
// +-------+------+
// | name|salary|
// +-------+------+
// |Michael| 3000|
// | Andy| 4500|
// | Justin| 3500|
// | Berta| 4000|
// +-------+------+
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show()
// +--------------+
// |average_salary|
// +--------------+
// | 3750.0|
// +--------------+
Datasource
Read and write into the default Parquet format
val usersDF = spark.read.load("examples/src/main/resources/users.parquet")
usersDF.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
Read data for a specific format. (json, parquet, jdbc, orc, libsvm, csv, text)
val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json")
peopleDF.select("name", "age").write.format("parquet").save("namesAndAges.parquet")
Run SQL on files directly:
val sqlDF = spark.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")
Saving DataFrame into persistent Hive tables
peopleDF.createOrReplaceTempView("people_table")
val resultsDF = spark.sql("SELECT name, age FROM people_table")
spark.table("people_table").write.saveAsTable("people_hive_table")
// Provide options and mode
spark.table("people_table").write.option("path", "/some/path").mode(SaveMode.Append).saveAsTable("people_hive_table")
Partitioning, Bucketing, Sortby
Hive table:
CREATE TABLE mytable (
name string,
city string,
employee_id int )
PARTITIONED BY (year STRING, month STRING, day STRING)
CLUSTERED BY (employee_id) INTO 256 BUCKETS
When we insert data into a partition for 2017-01-10. Hive will store data in a directory hierarchy:
/user/hive/warehouse/mytable/y=2015/m=12/d=02
Bucketing (clustering) result in a fixed number of files (256) buckets. What hive will do is to take the field, calculate a hash and assign a record to that bucket.
If we often query data by date, partitioning reduces file I/O. Bucketing allows data to spread evenly while easier to locate by hashing.
Bucket and sort are applicable to persistent tables. For file-based data source, partitioning is also available.
peopleDF.write.bucketBy(42, "name").sortBy("age").saveAsTable("people_bucketed")
peopleDF.write.partitionBy("age").format("parquet").save("namesPartByColor.parquet")
peopleDF.write
.partitionBy("age")
.bucketBy(42, "name")
.saveAsTable("people_partitioned_bucketed")
Full code example for the Datasource is available at [https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala]
Parquet
Parquet is a common columnar format for data processing systems. Spark SQL supports reading and writing Parquet files that preserves the schema of the data.
Read and write Parquet file
// Encoders for most common types are automatically provided by importing spark.implicits._
import spark.implicits._
val peopleDF = spark.read.json("examples/src/main/resources/people.json")
// DataFrames can be saved as Parquet files, maintaining the schema information
peopleDF.write.parquet("people.parquet")
// Read in the parquet file created above
// Parquet files are self-describing so the schema is preserved
// The result of loading a Parquet file is also a DataFrame
val parquetFileDF = spark.read.parquet("people.parquet")
// Parquet files can also be used to create a temporary view and then used in SQL statements
parquetFileDF.createOrReplaceTempView("parquetFile")
val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19")
namesDF.map(attributes => "Name: " + attributes(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
Partition
In a partitioned table, data are usually stored in different directories, with partitioning columns encoded as the partition directories.
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
By passing path/to/table to SparkSession.read.parquet or SparkSession.read.load, Spark SQL automatically extracts the partitioning information. The schema for the DataFrame:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
Schema merging
To merge 2 schema, for example, merge one table with the square of i and another table with the cub of i:
// This is used to implicitly convert an RDD to a DataFrame.
import spark.implicits._
// Create a simple DataFrame, store into a partition directory
val squaresDF = spark.sparkContext.makeRDD(1 to 5).map(i => (i, i * i)).toDF("value", "square")
squaresDF.write.parquet("data/test_table/key=1")
// Create another DataFrame in a new partition directory,
// adding a new column and dropping an existing column
val cubesDF = spark.sparkContext.makeRDD(6 to 10).map(i => (i, i * i * i)).toDF("value", "cube")
cubesDF.write.parquet("data/test_table/key=2")
// Read the partitioned table
val mergedDF = spark.read.option("mergeSchema", "true").parquet("data/test_table")
mergedDF.printSchema()
// The final schema consists of all 3 columns in the Parquet files together
// with the partitioning column appeared in the partition directory paths
// root
// |-- value: int (nullable = true)
// |-- square: int (nullable = true)
// |-- cube: int (nullable = true)
// |-- key: int (nullable = true)
JSON
// Primitive types (Int, String, etc) and Product types (case classes) encoders are
// supported by importing this when creating a Dataset.
import spark.implicits._
// A JSON dataset is pointed to by path.
// The path can be either a single text file or a directory storing text files
val path = "examples/src/main/resources/people.json"
val peopleDF = spark.read.json(path)
// The inferred schema can be visualized using the printSchema() method
peopleDF.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by spark
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
// +------+
// | name|
// +------+
// |Justin|
// +------+
// Alternatively, a DataFrame can be created for a JSON dataset represented by
// a Dataset[String] storing one JSON object per string
val otherPeopleDataset = spark.createDataset(
"""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val otherPeople = spark.read.json(otherPeopleDataset)
otherPeople.show()
// +---------------+----+
// | address|name|
// +---------------+----+
// |[Columbus,Ohio]| Yin|
// +---------------+----+
Hive
import java.io.File
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
case class Record(key: Int, value: String)
// warehouseLocation points to the default location for managed databases and tables
val warehouseLocation = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
import spark.sql
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sql("SELECT * FROM src").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// Aggregation queries are also supported.
sql("SELECT COUNT(*) FROM src").show()
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+
// The results of SQL queries are themselves DataFrames and support all normal functions.
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
// The items in DataFrames are of type Row, which allows you to access each column by ordinal.
val stringsDS = sqlDF.map {
case Row(key: Int, value: String) => s"Key: $key, Value: $value"
}
stringsDS.show()
// +--------------------+
// | value|
// +--------------------+
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// ...
// You can also use DataFrames to create temporary views within a SparkSession.
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
// Queries can then join DataFrame data with data stored in Hive.
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
// +---+------+---+------+
// |key| value|key| value|
// +---+------+---+------+
// | 2| val_2| 2| val_2|
// | 4| val_4| 4| val_4|
// | 5| val_5| 5| val_5|
// ...
JDBC
// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load()
val connectionProperties = new Properties()
connectionProperties.put("user", "username")
connectionProperties.put("password", "password")
val jdbcDF2 = spark.read
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save()
jdbcDF2.write
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Specifying create table column data types on write
jdbcDF.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
Logical and physical architecture
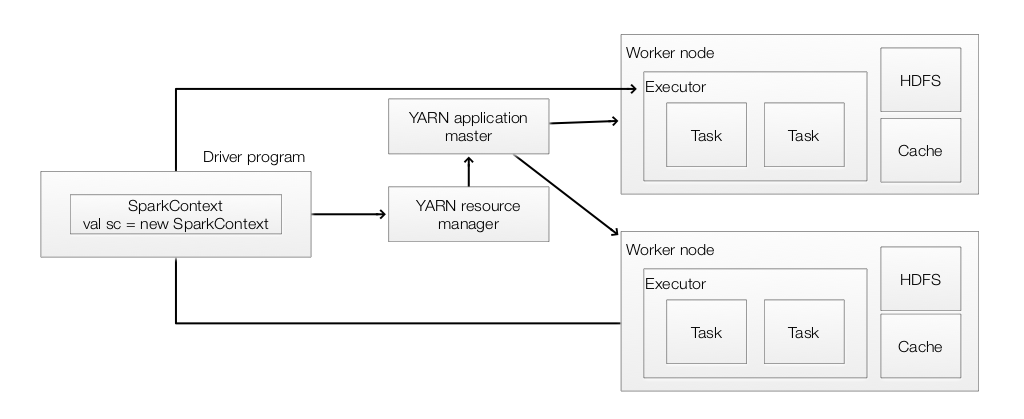
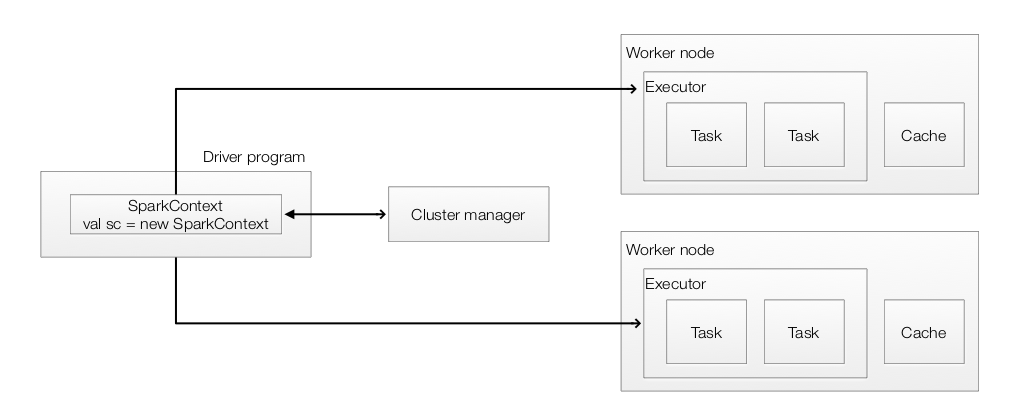
- Spark application consists of a driver program that runs the user’s main function to create a SparkContext.
- SparkContext coordinates independent set of processes on a cluster to perform parallel operations.
- SparkContext connects to several types of cluster managers (Spark’s standalone cluster manager, Mesos or YARN) which responsible for resource allocation.
- Once connected, Spark acquires executors on nodes in the cluster,
- Executors process and store data for your application.
- SparkContext sends the application code to the executors.
- SparkContext sends tasks to the executors to run.
- Data can be partitioned as a Hadoop file across the cluster that can be manipulated in parallel or as an existing Scala collection in the driver program.
Here is a Spark application running with a YARN cluster manager.