“Apache Storm”
Logical architecture
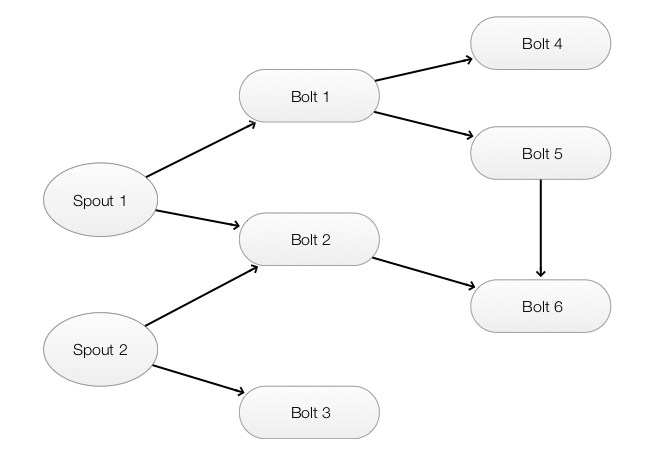
An Apache Storm application is called a topology. A topology is a graph of nodes that produce and transform data stream. It contains 2 types of nodes:
- Spout: Datasource that produce data streams. e.g. ((“Let’s produce word counts for this sentence.”), (“The second sentence to be counted.”), (“Third sentence.”)…)
- Bolt: Process and transfrom data stream. ((the, 1), (sentence, 3), (produce, 1), …)
Storm programming
Define a topology by chaining Spout and Bolt:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("word");
builder.setBolt("exclaim2", new ExclamationBolt(), 2).shuffleGrouping("exclaim1");
This topology contains a spout and two bolts. The spout TestWordSpout emits a word tuple, and each bolt appends an exclamation mark to the data stream. For the word tripe (“paul”), it passes through 2 bolts which at the end produces (“paul!!”).
The number parameter in setSpout and setBolt indicates a hint to the number of threads to run the spout or bolt. For example, in the example below, we want to run TestWordSpout in 10 threads to generate 10 words in parallel.
builder.setSpout("word", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3);
shuffleGrouping connects spouts and bolts to form a topology. Here we form a chain:
\[TestWordSpout \rightarrow ExclamationBolt \rightarrow ExclamationBolt\]builder.setSpout("word", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("word");
builder.setBolt("exclaim2", new ExclamationBolt(), 2).shuffleGrouping("exclaim1");
We can chain Spout and Bolt together as a graph structure:
builder.setSpout("word", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("word");
builder.setBolt("exclaim2", new ExclamationBolt(), 2).shuffleGrouping("word");
builder.setBolt("exclaim3", new ExclamationBolt(), 2).shuffleGrouping("exclaim1");
Spout
TestWordSpout provides a stream of tuple to the ExclamationBolt. Apache Storm calls nextTuple of a spout to produce new data. Here, for every 100 milli-seconds, we randomly select 1 of the five names and emit as a new datastream. e.g. (paul)
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"paul", "mary", "peter", "simon", "no one"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
Here is the full source code of a spout:
public class TestWordSpout extends BaseRichSpout {
public static Logger LOG = LoggerFactory.getLogger(TestWordSpout.class);
boolean _isDistributed;
SpoutOutputCollector _collector;
public TestWordSpout() {
this(true);
}
public TestWordSpout(boolean isDistributed) {
_isDistributed = isDistributed;
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
}
public void close() {
}
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"nathan", "mike", "jackson", "golda", "bertels"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
public void ack(Object msgId) {
}
public void fail(Object msgId) {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
if(!_isDistributed) {
Map<String, Object> ret = new HashMap<String, Object>();
ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 1);
return ret;
} else {
return null;
}
}
}
declarer declare the tuple to be emitted. Here, the tuple has only one field called “word”.
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
For example, we can declare a tuple containing 2 fields naming “word” and “count”.
new Fields("word", "count")
Apache Strom will callback ack if the tuple is completely and successfully processed by a topology. Otherwise, if it is timeout or failed, fail will be called. The Spout can put logic in fail to recover failure or to retry.
public void ack(Object msgId) {
}
public void fail(Object msgId) {
}
Bolt
A bolt consumes, processes or transforms input streams, and possibly emits new streams.
public static class ExclamationBolt extends BaseRichBolt {
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
// Append an exclamation mark to the input datastream "tuple"
// and emit it as the new datastream
_collector.emit(tuple, new Values(tuple.getString(0) + "!"));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
Important: It is important to acknowledge to Storm that this bolt successfully process the tuple.
_collector.ack(tuple)
We can run our topology in a local machine (local mode) for development or onto a cluster (remote mode). Here for remote mode, we set the number of workers (the number of standalone JVM instances to run the topology) and deploy the topology. For local mode, we run it in a local machine for 10s and then later kill and shutdown the topology.
public class ExclamationTopology {
public static class ExclamationBolt extends BaseRichBolt {
...
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("word");
builder.setBolt("exclaim2", new ExclamationBolt(), 2).shuffleGrouping("exclaim1");
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}
Remote mode command:
cd /usr/local/Cellar/storm/1.0.2/libexec/examples/storm-starter
storm jar storm-starter-topologies-1.0.2.jar org.apache.storm.starter.ExclamationTopology my_job
After the topology is launched, we can monitor it on http://localhost:8080.
Local mode command:
cd /usr/local/Cellar/storm/1.0.2/libexec/examples/storm-starter
storm jar storm-starter-topologies-1.0.2.jar org.apache.storm.starter.ExclamationTopology
Stream grouping
A topology specify which stream a bolt receive data from. Here bolt exclaim1 receies stream from the spout word. The number parameters indicates the amount of parallelism. For example, the exclamation bolt have a parallelism of 3. We start 3 executors each running in its own thread.
builder.setSpout("word", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("word");
Each executor run 1 or more tasks for the same bolt or spout. Nevertheless, it is 1 task per executor by default. A stream grouping defines how that stream should be partitioned among the bolt’s tasks. For example, the code above have 3 exclamation bolt tasks each can append an exclamation mark to a word.
In the code below, we use a SplitSentece bolt to split a sentence into words. We use shuffleGrouping to route it equally among the bolt’s tasks for load balancing. However, to have an accumulative count for each word, we want the same word tuple to route to the same task so we can have a single in-memory counter for each word. fieldsGrouping use the word field in the tuple to identify which bolt’s task to use.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new FastRandomSentenceSpout(), 4);
builder.setBolt("split", new SplitSentence(), 4).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 4).fieldsGrouping("split", new Fields("word"));
SplitSentence Bolt:
public static class SplitSentence extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for (String word: sentence.split("\\s+")) {
collector.emit(new Values(word, 1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
WordCount bolt:
public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
There are 8 stream grouping methods:
-
Shuffle grouping: Tuples are randomly distributed across the bolt’s tasks equally.
-
Fields grouping: The stream is partitioned by the fields specified in the grouping. For example, we can use a user id to determine which bolt task to handle a user.
-
Partial Key grouping: The stream is partitioned like the fields grouping but are load balanced between two downstream bolts.
-
All grouping: The stream is replicated across all the bolt’s tasks.
-
Global grouping: The entire stream goes to the bolt’s task with the lowest bolt id.
-
None grouping: Don’t care.
-
Direct grouping: Producer decides which task to consume it.
-
Local or shuffle grouping: Use task in the same local process if possible. Otherwise, use shuffle grouping.
Guaranteeing Message Processing
A spout can trigger many tuples to be processed by bolts. Apache Storm provides certain guarantee of message processing. Apache Storm consider a tuple is processed only if all the downstream bolts have completely and successfully process the tuple. By default, Apache storm will timeout and fail the processing in 30s.
TopologyBuilder builder = new TopologyBuilder();
// Read many sentences at once, split them into words and count each word occurance.
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com", 22133,"sentence_queue", new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10).shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20).fieldsGrouping("split", new Fields("word"));
To emit a tuple from a spout with the guaranteeing processing, we need to add a message ID when emitting it. For example, we can read a message from a message queue and re-use the message ID as our tuple message ID.
_collector.emit(new Values("field1", "field2", 3) , msgId);
If all the downstream bolts have successfully process it, Apache Storm will callback the ack in the Spout. We can then implement code to commit the message transaction in the original queue so it can be dequeued. If the process timeout or fail, fail will be called. We can put logic there for recovery or retry. For example, we may rollback the message transaction so a Spout can deque it again later.
Apache Storm guaranteeing message processing does not handle message retry. It is our responsibility to implement the retry logic which can be as easy as failing the message transaction.
To support Guaranteeing Message Processing, we need to implement 2 more things in the bolts:
- Identify the source of the tuple if emitting tuples inside a bolt. (anchoring) Without the source tuple, Apache Storm assumes all the downstream bolts’ processing is succesful.
public void execute(Tuple tuple) { ... _collector.emit(tuple, new Values(word)); ... } - Acknowledge that a bolt have successfully processed the tuple. A bolt is only responsible for itself. Apache Storm maintains a graph indicating which bolts have acknowledge the processing. So ack as soon as a bolt have successful finish its logic without knowing whether the downstream bolts may success or fail.
_collector.ack(tuple);
Here is the full source code for the bolt:
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
Does not ack or fail a stream will result in memory leak.
Anchoring
We can anchoring a new emitted tuple with multiple sources:
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));
Performance
In some application, like log processing, guaranteeing message processing is not necessary. For those cases, we can turn it off to improve performance. To turn it off, we can:
- Set Config.TOPOLOGY_ACKERS to 0 such that ack is send immediately after a tuple is emitted from a spout.
- Do not provide a message ID when emit a tuple from the spout.
- Emit tuple in bolts as un-anchored.
Storm logical model for parallelism
The basic unit in our logical model is task. Tasks are group into executors (aka # of parallelism). The yellow spout has a parallelism of 4 and therefore 4 executors. However, an executor can own more than 1 task if the number of tasks are explicitly defined. For example, for the green bolt, we define 4 tasks with a parallelism of 2. Therefore, the green bolts have 2 executors each containing 2 tasks.
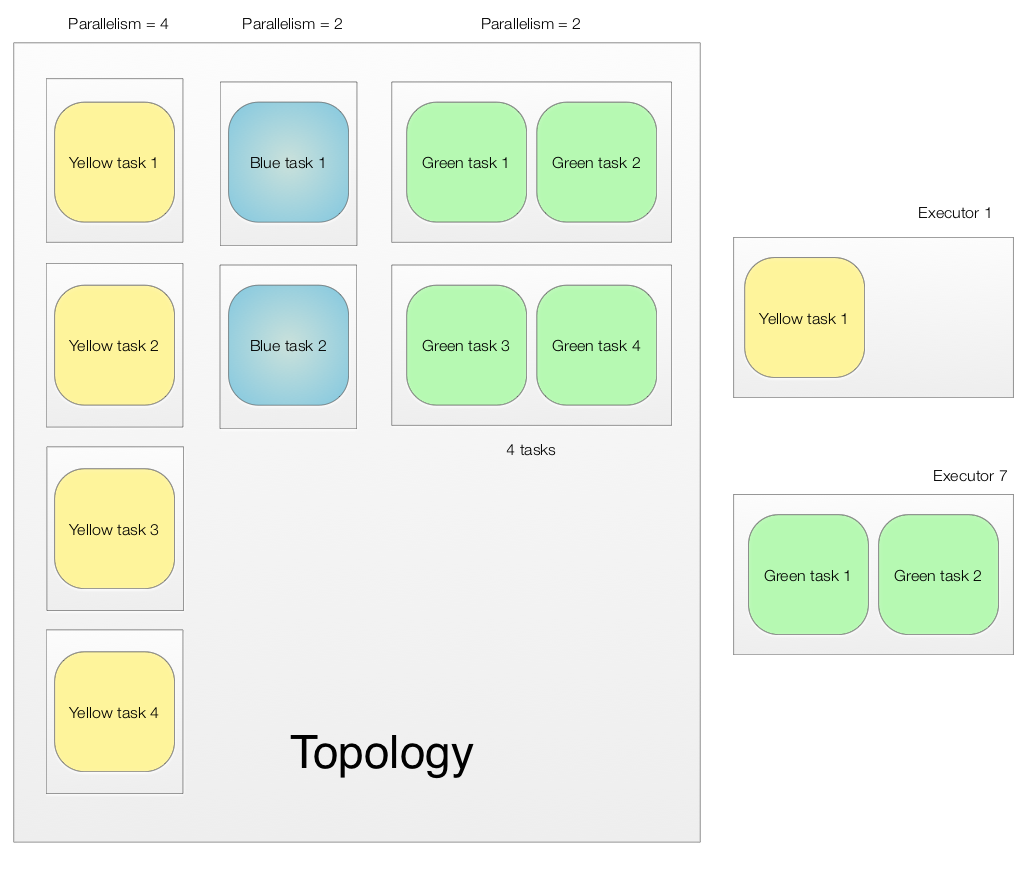
Here is the Storm topology coding:
Config conf = new Config();
// use two worker processes
conf.setNumWorkers(2);
// set parallelism hint to 2
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
// Set 4 tasks for the green bolt
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 4)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());
Physical model
In our topology, we also define the number of worker processess. Each process runs in a separate JVM process and can run on the same machine or any machine in the cluster. Each executor is run on a single thread. Therefore, the following is how our logical model map into 2 worker processes.
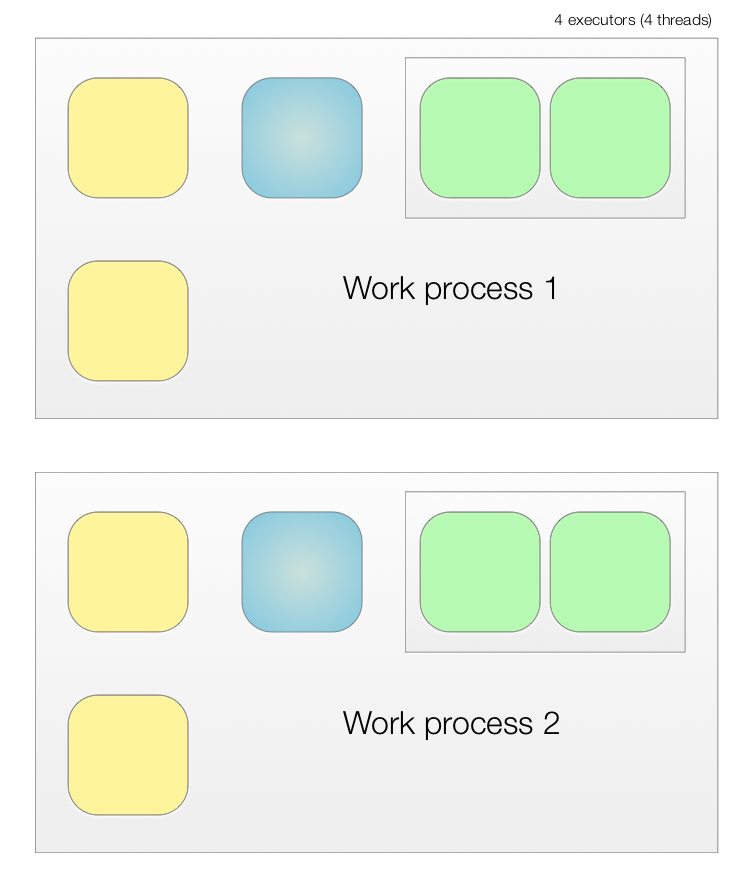
The topology can be reconfigured with different worker process and executors in the command line.
## Reconfigure the topology "mytopology" to use 5 worker processes,
## the spout "blue-spout" to use 3 executors and
## the bolt "yellow-bolt" to use 10 executors.
$ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
Physical architecture
There are two kinds of nodes on a Storm cluster:
- the master node runs a daemon nimbus: Distributes code around the cluster, assign tasks to supervisors and monitor failures.
- the worker nodes runs a daemon supervisor: Starts and stops worker processes.
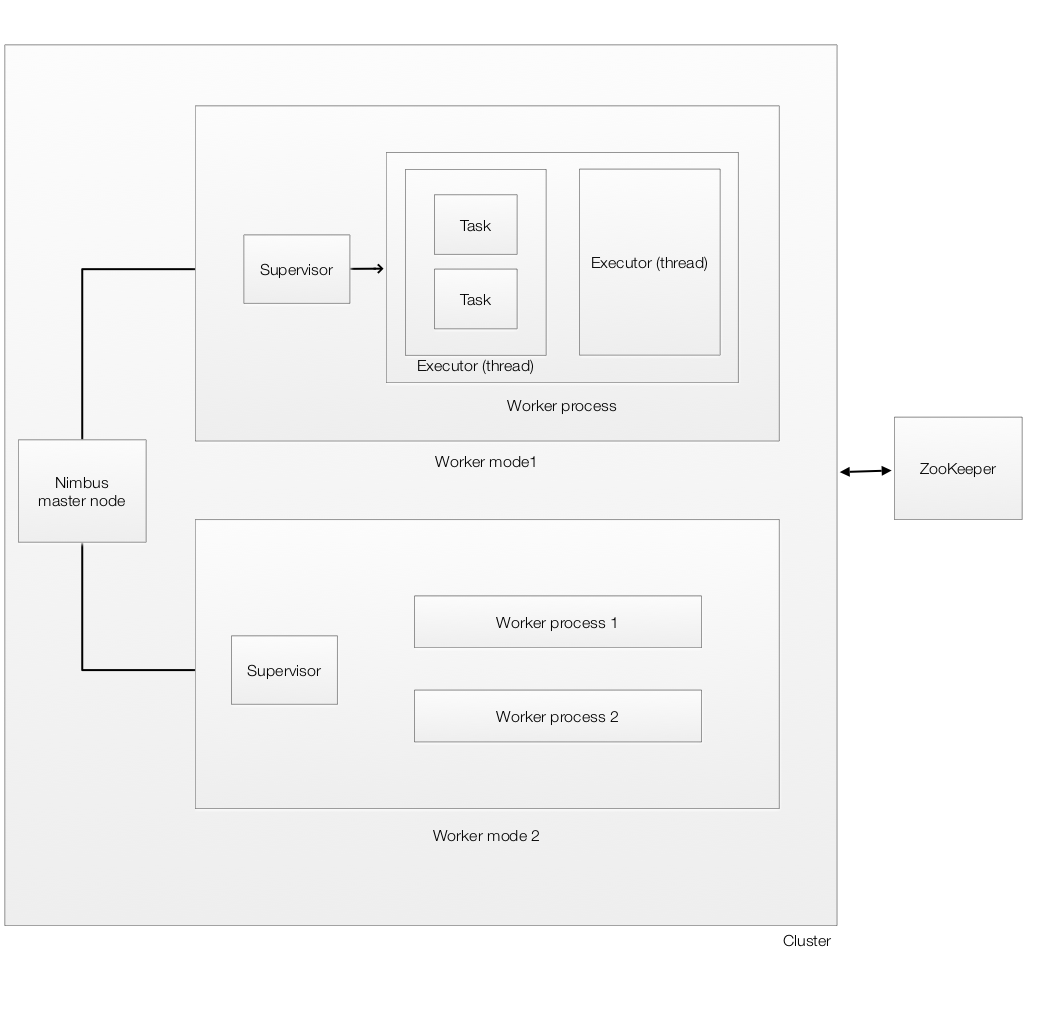
The ZooKeep is used to store the state of the clusters.
Failure
When a worker dies, the supervisor will restart it. If it continues fails and unable to send heartbeat to Nimbus, Nimbus will reschedule the worker. If a node die, all tasks on that node will be reassigned to other nodes. We need to use tools like daemontools or monit to auto-restart the nimbus or supervisor. Nimbus and supervisor are stateless which Zookeeper hold the state. Once the daemon is restarted, it behaves as if it never occurred. We can have backup Nimbus. If the Nimbus node failed, a new Nimbus will be elected and take over the responsibility.
Scheduler
Apache Storm has 4 built-in schedulers to manage resource usage: DefaultScheduler, IsolationScheduler, MultitenantScheduler, ResourceAwareScheduler.
For example, the isolation scheduler specifies which topologies run on a dedicated set of machines isolated from other topologies. It receives higher priority, so resources are allocated to isolated topologies first while the remaining machines on the cluster are shared among other topologies.
Example in configure an isolation scheduler:
storm.scheduler: “org.apache.storm.scheduler.IsolationScheduler”
isolation.scheduler.machines:
"topology-1": 4
"topology-2": 2
(info) Assign to the number of machines.
Trident
Trident is an extension of Storm. Here we create a spout that cycle through 4 tuples.
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout.setCycle(true);
To build a Trident topology for a word counter using built-in processing functions:
TridentTopology topology = new TridentTopology();
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);
Trident processes the stream as batches of tuples (instead of streaming) on the order of thousands or millions of tuples. The sentence is splited and the stream is grouped by the “word” field. Then, each group is persistently aggregated using the Count aggregator. persistentAggregate function store and update the results of the aggregation (word count) in a source of state (memory).
Trident provides query, joins, aggregations, grouping, functions, and filters:
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
It adds primitives for doing stateful, incremental processing on top of any database or persistence store.
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
In the example above, we use memory as a source of state. Alternatively, we can use Memcached to persist the information.
.persistentAggregate(MemcachedState.transactional(serverLocations), new Count(), new Fields("count"))
MemcachedState.transactional()
Trident also has exactly-once guarantee message processing.
Here is the full source code which we also add a distributed RPC as a source and a topology to process the word count:
topology.newDRPCStream("words", drpc)
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
public class TridentWordCount {
public static class Split extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for (String word : sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
public static StormTopology buildTopology(LocalDRPC drpc) {
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3, new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"), new Values("four score and seven years ago"),
new Values("how many apples can you eat"), new Values("to be or not to be the person"));
spout.setCycle(true);
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"),
new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(),
new Count(), new Fields("count")).parallelismHint(16);
topology.newDRPCStream("words", drpc).each(new Fields("args"), new Split(), new Fields("word")).groupBy(new Fields(
"word")).stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count")).each(new Fields("count"),
new FilterNull()).aggregate(new Fields("count"), new Sum(), new Fields("sum"));
return topology.build();
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setMaxSpoutPending(20);
if (args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordCounter", conf, buildTopology(drpc));
for (int i = 0; i < 100; i++) {
System.out.println("DRPC RESULT: " + drpc.execute("words", "cat the dog jumped"));
Thread.sleep(1000);
}
} else {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, buildTopology(null));
}
}
}
Installation & operation
Install Zookeeper and Apache Storm:
brew install zookeeper
brew install storm
Edit Apache Storm configuration:
vim /usr/local/opt/storm/libexec/conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
nimbus.seeds: ["localhost"]
Start Zookeeper
zkServer start
Start Apache Storm
Start Storm
storm nimbus
storm supervisor
storm ui
Verify:
jps
29126 Jps
29065 LogWriter
29066 LogWriter
29067 LogWriter
29100 core
29069 worker
29070 worker
29071 worker
29041 supervisor
29075 LogWriter
29076 worker
28917 QuorumPeerMain
28986 nimbus
Apache Storm UI tool
http://localhost:8080
To run a Apache Storm topology:
cd /usr/local/Cellar/storm/1.0.2/libexec/examples/storm-starter
storm jar storm-starter-topologies-1.0.2.jar org.apache.storm.starter.ExclamationTopology my_job