“Apache Kafka”
Apache Kafka is a distributed streaming messaging platform.
Topics and logs
Producers produce records (aka message). Each record is routed and stored in a specific partition based on a partitioner.
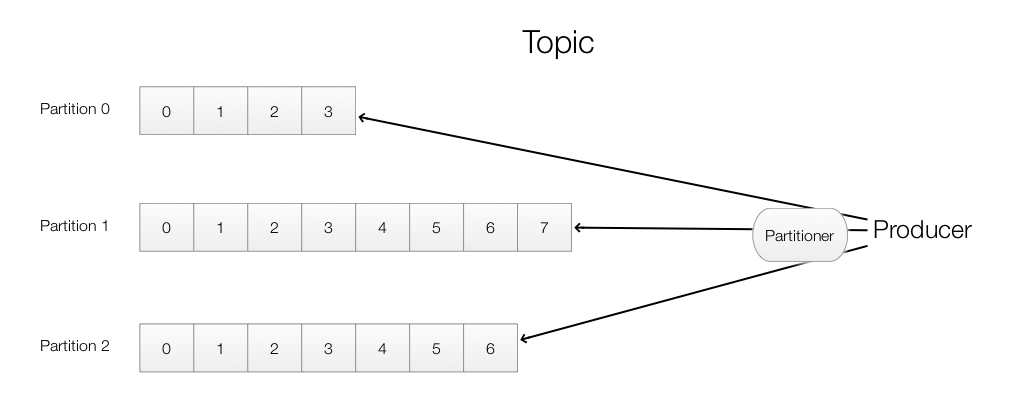
By default, the built-in DefaultPartitioner uses a hash function based on the record key to determine the partition that the record is stored.
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; // murmur2 is a Hash function
Here is the sample code for a Producer to send 100 records to my-topic.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
...
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++) {
// send(topic name, record key, record value)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
}
producer.close();
Kafka replicate each partition across a configurable number of servers for fault tolerance.
Consumer consumes records in a topic
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
...
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
Each consumer belongs to a consumer group. Each record in a topic is processed by a member of a consumer group:
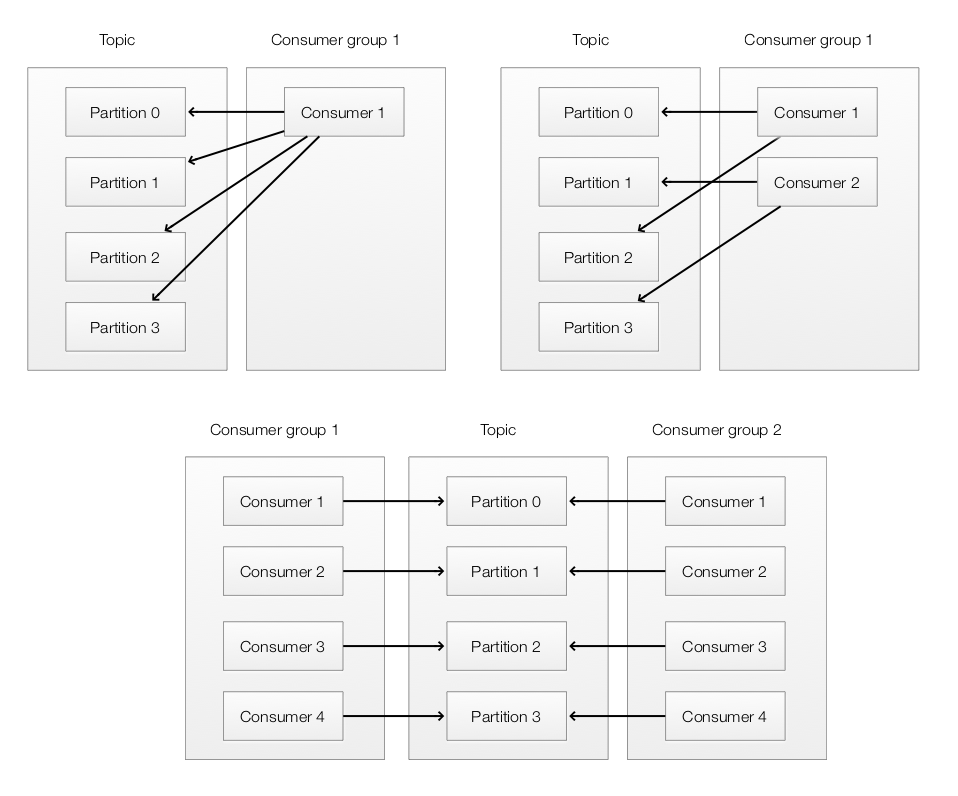
Kafka maintains an offset for each consumer group. The offset is controlled by the consumer which it can be advanced after reading the record. A consumer can also rewind or skip records.
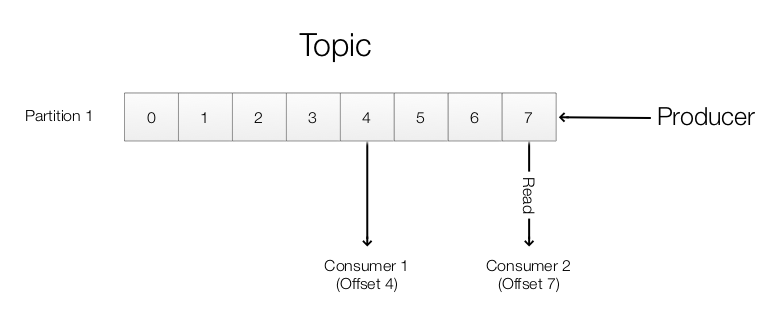
The Kafka cluster retains all records until a configured retention period is expired. For example, if the retention period is 2 days, the records will be kept for 2 days no matter it is consumed or not. After 2 days, they will be removed to free up space.
To explicitly specify the consumer group:
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);```
...
Basic
Kafka requires ZooKeeper. It provides application synchronization services. We start ZooKeeper and then Kafka.
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
Create a topic and list all topics
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
bin/kafka-topics.sh --list --zookeeper localhost:2181
Send messages
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
Start a consumer
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
Modify and delete a topic
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic Hello-kafka --partitions 2
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafka
Set up 2 more brokers in a multi-broker cluster
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
Start the 2 other server:
bin/kafka-server-start.sh config/server-1.properties
bin/kafka-server-start.sh config/server-2.properties &
Create a topic with replication factor of 3.
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Describe topics:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Which the leader of partition 0 is 1 with replicas 1, 2 and 0. All replicas 1, 2 and 0 are in-sync (Isr field)
We can kill server 1 and we can see the leader is switched to 2.
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
Producer
package kafka.examples;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class Producer extends Thread {
private final KafkaProducer<Integer, String> producer;
private final String topic;
private final Boolean isAsync;
public Producer(String topic, Boolean isAsync) {
Properties props = new Properties();
props.put("bootstrap.servers", KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);
props.put("client.id", "DemoProducer");
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<>(props);
this.topic = topic;
this.isAsync = isAsync;
}
public void run() {
int messageNo = 1;
while (true) {
String messageStr = "Message_" + messageNo;
long startTime = System.currentTimeMillis();
if (isAsync) { // Send asynchronously
producer.send(new ProducerRecord<>(topic,
messageNo,
messageStr), new DemoCallBack(startTime, messageNo, messageStr));
} else { // Send synchronously
try {
producer.send(new ProducerRecord<>(topic,
messageNo,
messageStr)).get();
System.out.println("Sent message: (" + messageNo + ", " + messageStr + ")");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
++messageNo;
}
}
}
class DemoCallBack implements Callback {
private final long startTime;
private final int key;
private final String message;
public DemoCallBack(long startTime, int key, String message) {
this.startTime = startTime;
this.key = key;
this.message = message;
}
/**
* A callback method the user can implement to provide asynchronous handling of request completion. This method will
* be called when the record sent to the server has been acknowledged. Exactly one of the arguments will be
* non-null.
*
* @param metadata The metadata for the record that was sent (i.e. the partition and offset). Null if an error
* occurred.
* @param exception The exception thrown during processing of this record. Null if no error occurred.
*/
public void onCompletion(RecordMetadata metadata, Exception exception) {
long elapsedTime = System.currentTimeMillis() - startTime;
if (metadata != null) {
System.out.println(
"message(" + key + ", " + message + ") sent to partition(" + metadata.partition() +
"), " +
"offset(" + metadata.offset() + ") in " + elapsedTime + " ms");
} else {
exception.printStackTrace();
}
}
}
Consumer
package kafka.examples;
import kafka.utils.ShutdownableThread;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Collections;
import java.util.Properties;
public class Consumer extends ShutdownableThread {
private final KafkaConsumer<Integer, String> consumer;
private final String topic;
public Consumer(String topic) {
super("KafkaConsumerExample", false);
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "DemoConsumer");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
this.topic = topic;
}
@Override
public void doWork() {
consumer.subscribe(Collections.singletonList(this.topic));
ConsumerRecords<Integer, String> records = consumer.poll(1000);
for (ConsumerRecord<Integer, String> record : records) {
System.out.println("Received message: (" + record.key() + ", " + record.value() + ") at offset " + record.offset());
}
}
@Override
public String name() {
return null;
}
@Override
public boolean isInterruptible() {
return false;
}
}
Streaming API
The Streams API allows an application to act as a stream processor to transform the input streams to output streams. It consuming an input stream from topic(s) and producing an output stream to topic(s). Here, we read from TextLinesTopic, transform the line stream into word count stream and publish it to WordsWithCountsTopic.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.kstream.KTable;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count("Counts");
wordCounts.to(Serdes.String(), Serdes.Long(), "WordsWithCountsTopic");
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
Kafka and Spark Streaming integration
Producer and consumer using Spark streaming with Kafka:
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
/**
* Consumes messages from one or more topics in Kafka and does wordcount.
* Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>
* <zkQuorum> is a list of one or more zookeeper servers that make quorum
* <group> is the name of kafka consumer group
* <topics> is a list of one or more kafka topics to consume from
* <numThreads> is the number of threads the kafka consumer should use
*
* Example:
* `$ bin/run-example \
* org.apache.spark.examples.streaming.KafkaWordCount zoo01,zoo02,zoo03 \
* my-consumer-group topic1,topic2 1`
*/
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
// Produces some random words between 1 and 100.
object KafkaWordCountProducer {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCountProducer <metadataBrokerList> <topic> " +
"<messagesPerSec> <wordsPerMessage>")
System.exit(1)
}
val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args
// Zookeeper connection properties
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
// Send some messages
while(true) {
(1 to messagesPerSec.toInt).foreach { messageNum =>
val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString)
.mkString(" ")
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
}
Thread.sleep(1000)
}
}
}
Kafka and Storm integration
Storm Spout as consumer:
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName, UUID.randomUUID().toString());
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
Storm Bolt as producer:
TopologyBuilder builder = new TopologyBuilder();
Fields fields = new Fields("key", "message");
FixedBatchSpout spout = new FixedBatchSpout(fields, 4,
new Values("storm", "1"),
new Values("trident", "1"),
new Values("needs", "1"),
new Values("javadoc", "1")
);
spout.setCycle(true);
builder.setSpout("spout", spout, 5);
//set producer properties.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaBolt bolt = new KafkaBolt()
.withProducerProperties(props)
.withTopicSelector(new DefaultTopicSelector("test"))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper());
builder.setBolt("forwardToKafka", bolt, 8).shuffleGrouping("spout");
Config conf = new Config();
StormSubmitter.submitTopology("kafkaboltTest", conf, builder.createTopology());