“CUDA Tutorial”
Sample code in adding 2 numbers with a GPU
Terminology: Host (a CPU and host memory), device (a GPU and device memory).
This sample code adds 2 numbers together with a GPU:
- Define a kernel (a function to run on a GPU).
- Allocate & initialize the host data.
- Allocate & initialize the device data.
- Invoke a kernel in the GPU.
- Copy kernel output to the host.
- Cleanup.
Define a kernel
Use the keyword __global__ to define a kernel. A kernel is a function to be run on a GPU instead of a CPU. This kernel adds 2 numbers \(a\) & \(b\) and store the result in \(c\).
// Kernel definition
// Run on GPU
// Adding 2 numbers and store the result in c
__global__ void add(int *a, int *b, int *c)
{
*c = *a + *b;
}
Allocate & initialize host data
In the host, allocate the input and output parameters for the kernel call, and initiate all input parameters.
int main(void) {
// Allocate & initialize host data - run on the host
int a, b, c; // host copies of a, b, c
a = 2;
b = 7;
...
}
Allocate and copy host data to the device
A CUDA application manages the device space memory through calls to the CUDA runtime. This includes device memory allocation and deallocation as well as data transfer between the host and device memory.
We allocate space in the device so we can copy the input of the kernel (\(a\) & \(b\)) from the host to the device. We also allocate space to copy result from the device to the host later.
int main(void) {
...
int *d_a, *d_b, *d_c; // device copies of a, b, c
// Allocate space for device copies of a, b, c
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Copy a & b from the host to the device
cudaMemcpy(d_a, &a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &b, size, cudaMemcpyHostToDevice);
...
}
Invoke the kernel
Invoke the kernel add with parameters for \(a, b, c.\)
int main(void) {
...
// Launch add() kernel on GPU with parameters (d_a, d_b, d_c)
add<<<1,1>>>(d_a, d_b, d_c);
...
}
To provide data parallelism, a multithreaded CUDA application is partitioned into blocks of threads that execute independently (and often concurrently) from each other. Each parallel invocation of add is referred to as a block. Each block have multiple threads. These block of threads can be scheduled on any of the available streaming multiprocessors (SM) within a GPU. In our simple example, since we just add one pair of numbers, we only need 1 block containing 1 thread (<<<1,1>>>).
In contrast to a regular C function call, a kernel can be executed N times in parallel by M CUDA threads (<<<N, M>>>). On current GPUs, a thread block may contain up to 1024 threads.
Copy kernel output to the host
Copy the addition result from the device to the host:
// Copy result back to the host
cudaMemcpy(&c, d_c, size, cudaMemcpyDeviceToHost);
Clean up
Clean up memory:
// Cleanup
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
Putting together: Heterogeneous Computing
In CUDA, we define a single file to run both the host and the device code.
nvcc add.cu # Compile the source code
a.out # Run the code.
The following is the complete source code for our example.
// Kernel definition
// Run on GPU
__global__ void add(int *a, int *b, int *c) {
*c = *a + *b;
}
int main(void) {
// Allocate & initialize host data - run on the host
int a, b, c; // host copies of a, b, c
a = 2;
b = 7;
int *d_a, *d_b, *d_c; // device copies of a, b, c
// Allocate space for device copies of a, b, c
int size = sizeof(int);
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Copy a & b from the host to the device
cudaMemcpy(d_a, &a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &b, size, cudaMemcpyHostToDevice);
// Launch add() kernel on GPU
add<<<1,1>>>(d_a, d_b, d_c);
// Copy result back to the host
cudaMemcpy(&c, d_c, size, cudaMemcpyDeviceToHost);
// Cleanup
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}
CUDA logical model
add<<<4,4>>>(d_a, d_b, d_c);
A CUDA applications composes of multiple blocks of threads (a grid) with each thread calls a kernel once.
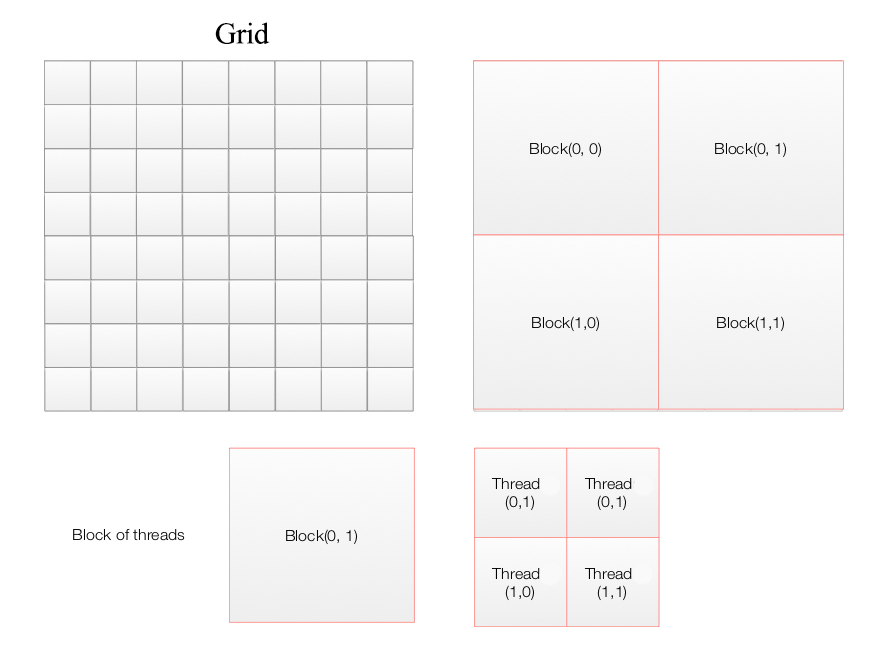
In the second example, we have 6 blocks and 12 threads per block.
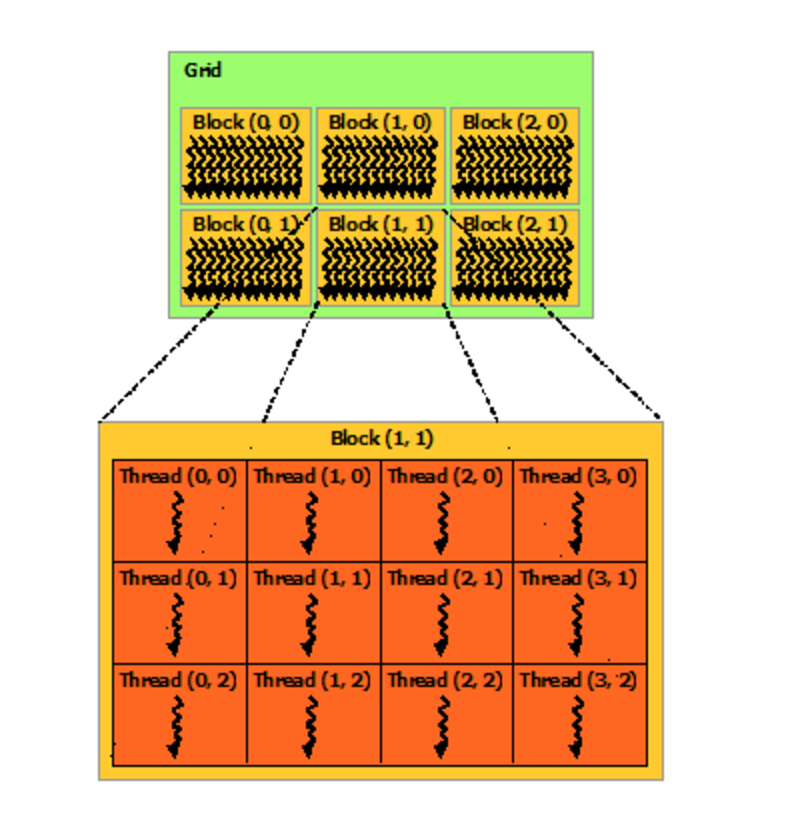
(source: Nvidia)
GPU physical model
A GPU composes of many Streaming Multiprocessors (SMs) with a global memory accessible by all SMs and a local memory.
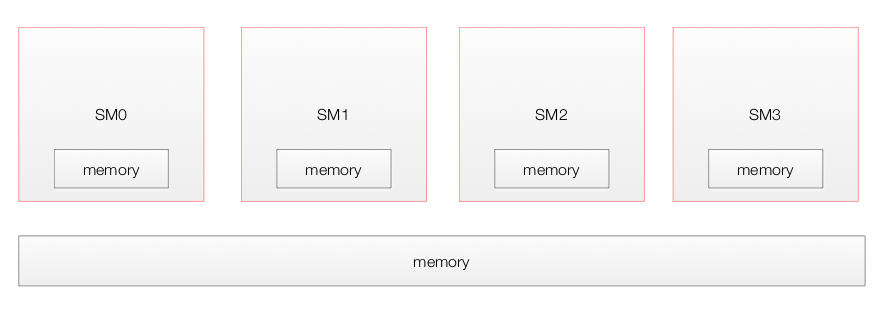
Each SM contains multiple cores which share a shared memory as well as one local to itself.
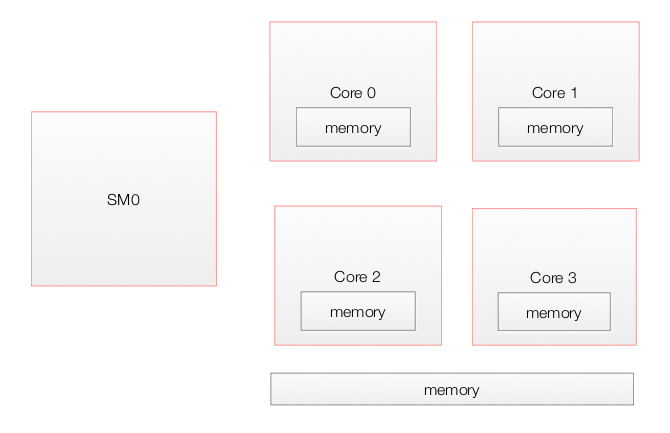
Here is the architect for GeoForce 8800 with 16 SMs each with 8 cores (Streaming processing SP).
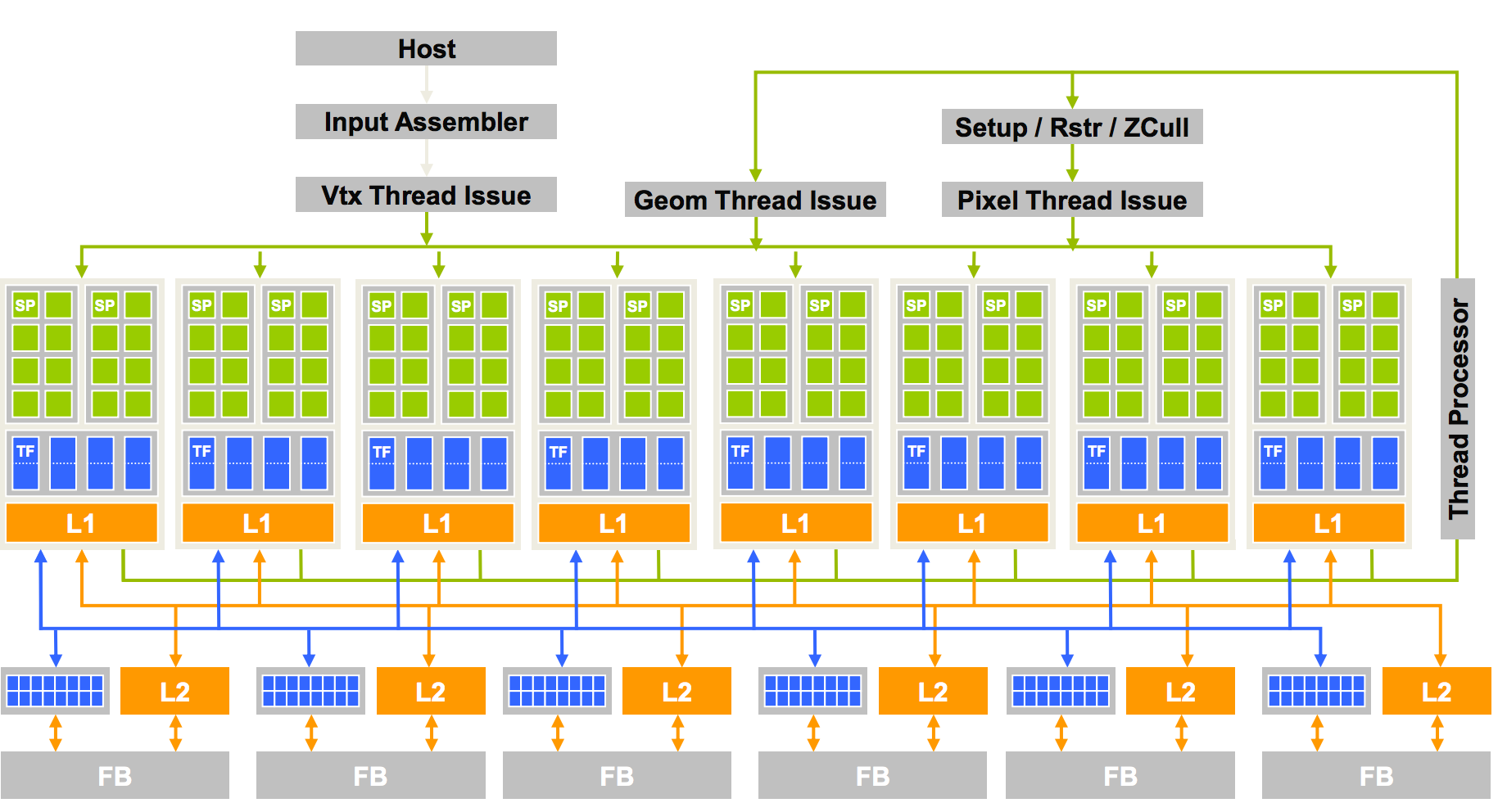
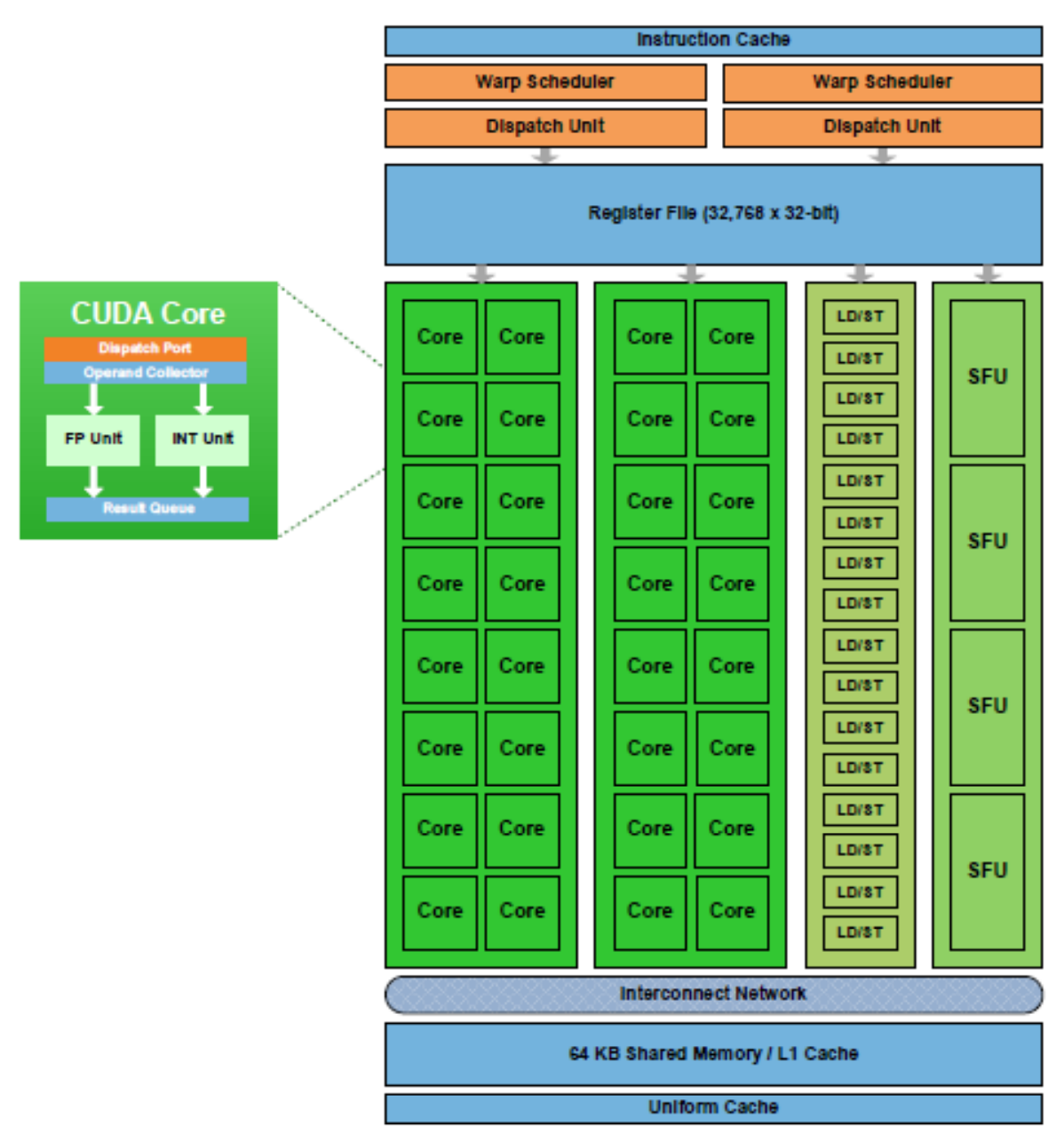
A SM in the Fermi architecture:
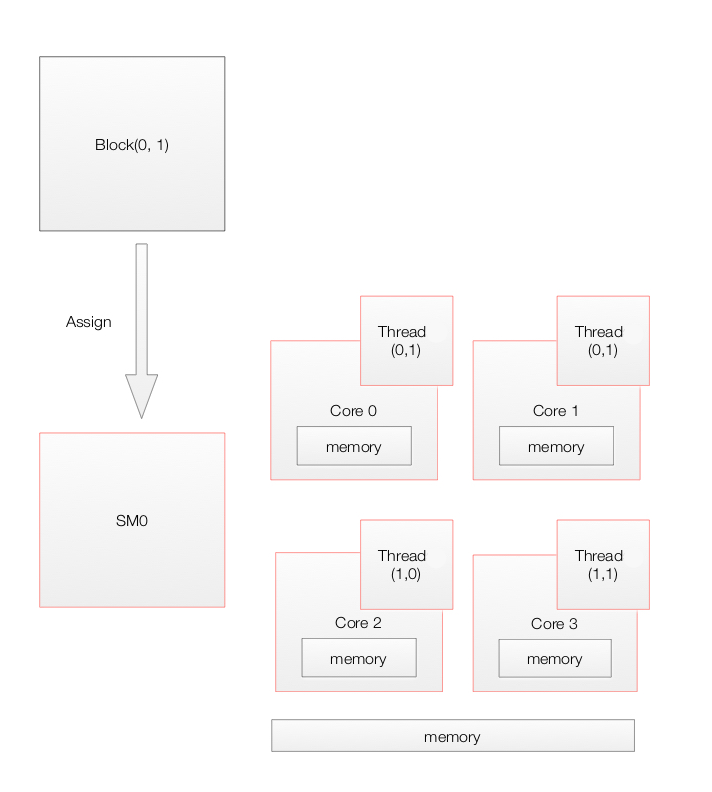
Execution model
Device level
When a CUDA application on the host invokes a kernel grid, the blocks of the grid are enumerated and a global work distribution engine assign them to SM with available execution capacity. Threads of the same block always run on the same SM. Multiple thread blocks and multiple threads in a thread block can execute concurrently on one SM. As thread blocks terminate, new blocks are launched on the vacated multiprocessors.
All threads in a grid execute the same kernel. GPU can handle multiple kernels from the same application simultaneously. Pascal GP100 can handle maximum of 32 thread blocks and 2048 threads per SM.
Here, we have a CUDA application composes of 8 blocks. It can be executed on a GPU with 2 SMs or 4SMs. With 4 SMs, block 0 & 4 is assigned to SM0, block 1, 5 to SM1, block 2, 6 to SM2 and block 3, 7 to SM3.
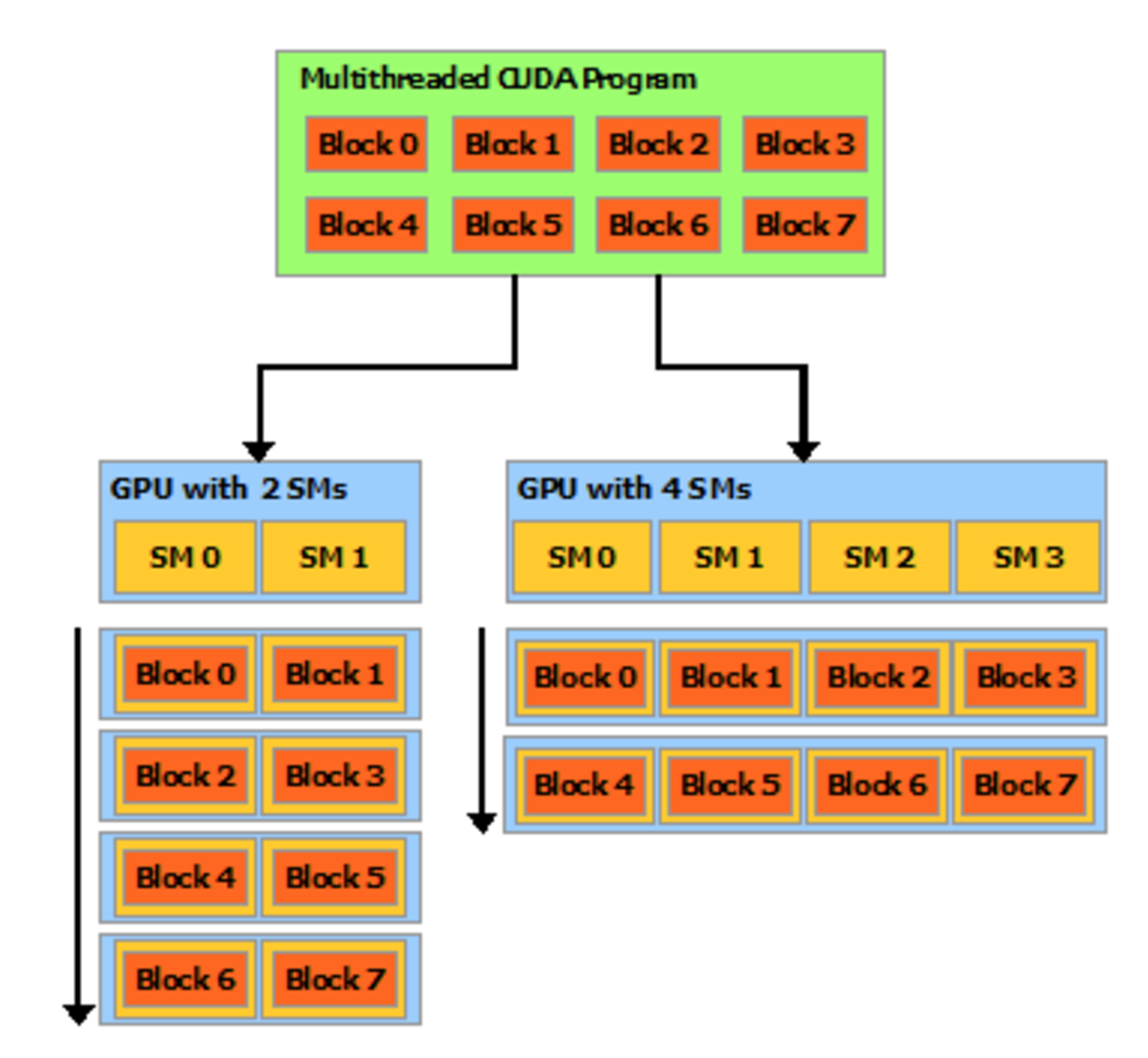
(source: Nvidia)
The entire device can only process one single application at a time and switch between applications is slow.
SM level
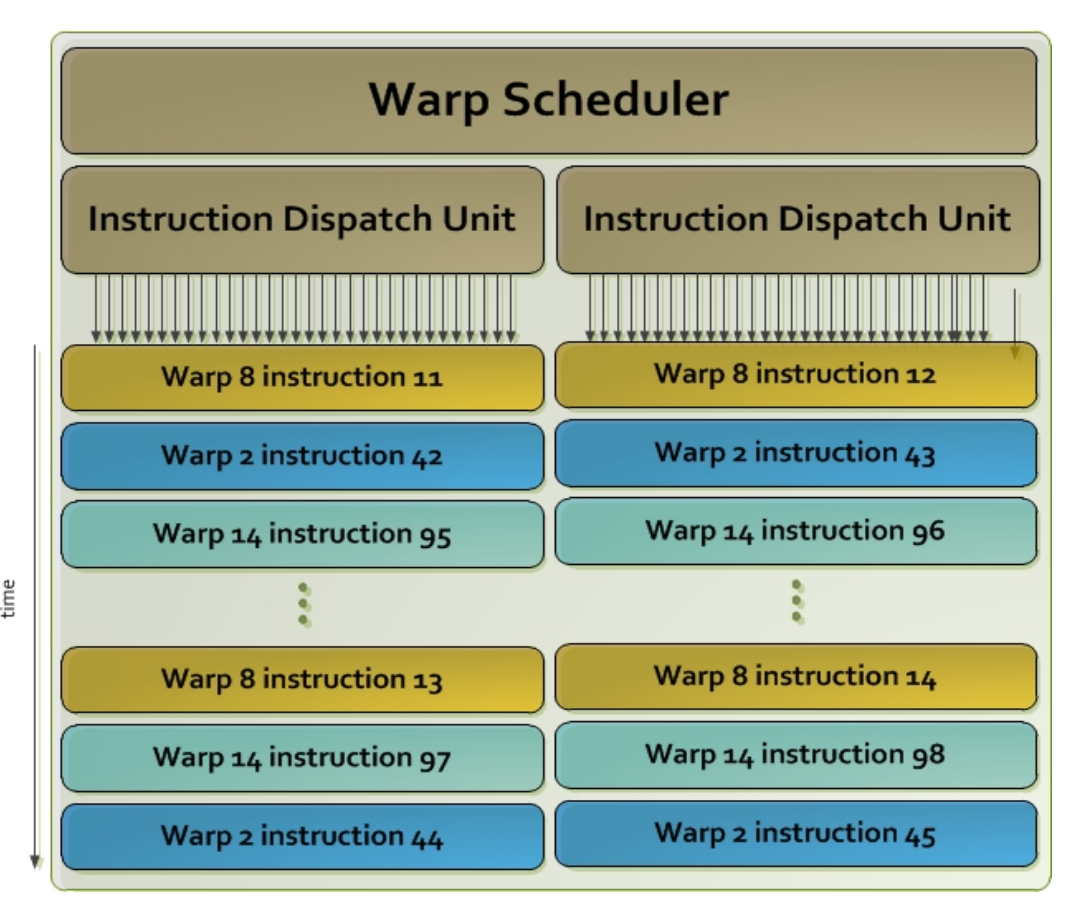
Once a block of threads is assigned to a SM, the threads are divided into units called warps. A block is partitioned into warps with each warp contains threads of consecutive, increasing thread IDs with the first warp containing thread 0.The size of a warp is determined by the hardware implementation. A warp scheduler selects a warp that is ready to execute its next instruction. In Fremi architect, the warp scheduler schedule a warp of 32 threads. Each warp of threads runs the same instruction. In the diagram below, we have 2 dispatch unit. Each one runs a different warp. In each warp, it runs the same instruction. When the threads in a warp is wait for the previous instruction to complete, the warp scheduler will select another warp to execute. Two warps from different blocks or different kernels can be executed concurrently.
Branch divergence
A warp executes one common instruction at a time. Each core (SP) run the same instruction for each threads in a warp. To execute a branch like:
if (a[index]==0)
a[index]++;
else
a[index]--;
SM skips execution of a core subjected to the branch conditions:
| c0 (a=3) | c1(a=3) | c2 (a=-3) | c3(a=7) | c4(a=2) | c5(a=6) | c6 (a=-2) | c7 (a=-1) | |
| if a[index]==0 | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ |
| a[index]++ | ↓ | ↓ | ↓ | ↓ | ↓ | |||
| a[index]– | ↓ | ↓ | ↓ |
So full efficiency is realized when all 32 threads of a warp branch to the same execution path. If threads of a warp diverge via a data-dependent conditional branch, the warp serially executes each branch path taken, disabling threads that are not on that path, and when all paths complete, the threads converge back to the same execution path.
To maximize throughput, all threads in a warp should follow the same control-flow. Program can be rewritten such that threads within a warp branch to the same code:
if (a[index]<range)
... // More likely, threads with a warp will branch the same way.
else
...
is preferred over
if (a[index]%2==0)
...
else
...
For loop unrolling is another technique to avoid branching:
for (int i=0; i<4; i++)
c[i] += a[i];
c[0] = a[0] + a[1] + a[2] + a[3];
Memory model
Every SM has a shared memory accessible by all threads in the same block. Each thread has its own set of registers and local memory. All blocks can access a global memory, a constant memory(read only) and a texture memory. (read only memory for spatial data.)
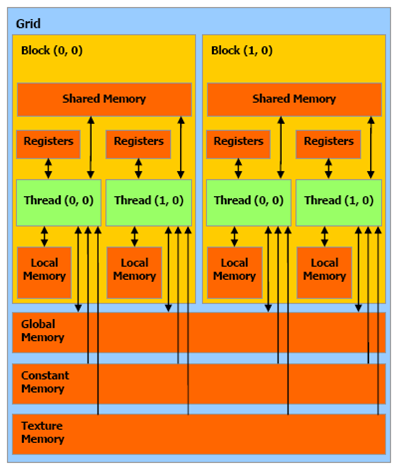
Local, Global, Constant, and Texture memory all reside off chip. Local, Constant, and Texture are all cached. Each SM has a L1 cache for global memory references. All SMs share a second L2 cache. Access to the shared memory is in the TB/s. Global memory is an order of magnitude slower. Each GPS has a constant memory for read only with shorter latency and higher throughput. Texture memory is read only.
| Type | Read/write | Speed |
|---|---|---|
| Global memory | read and write | slow, but cached |
| Texture memory | read only | cache optimized for 2D/3D access pattern |
| Constant memory | read only | where constants and kernel arguments are stored |
| Shared memory | read/write | fast |
| Local memory | read/write | used when it does not fit in to registers part of global memory slow but cached |
| Registers | read/write | fast |
Local memory is just thread local global memory. It is much slower than either registers or shared memory.
Speed (Fast to slow):
- Register file
- Shared Memory
- Constant Memory
- Texture Memory
- (Tie) Local Memory and Global Memory
| Declaration | Memory | Scope | Lifetime |
| int v | register | thread | thread |
| int vArray[10] | local | thread | thread |
| __shared__ int sharedV | shared | block | block |
| __device__ int globalV | global | grid | application |
| __constant__ int constantV | constant | grid | application |
When threads in a warp load data from global memory, the system detects whether they are consecutive. It combines consecutive accesses into one single access to DRAM.
Shared memory
Shared memory is on-chip and is much faster than local and global memory. Shared memory latency is roughly 100x lower than uncached global memory latency. Threads can access data in shared memory loaded from global memory by other threads within the same thread block. Memory access can be controlled by thread synchronization to avoid race condition (__syncthreads). Shared memory can be uses as user-managed data caches and high parallel data reductions.
Static shared memory:
#include
__global__ void staticReverse(int *d, int n)
{
__shared__ int s[64];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t];
// Will not conttinue until all threads completed.
__syncthreads();
d[t] = s[tr];
}
int main(void)
{
const int n = 64;
int a[n], r[n], d[n];
for (int i = 0; i < n; i++) {
a[i] = i;
r[i] = n-i-1;
d[i] = 0;
}
int *d_d;
cudaMalloc(&d_d, n * sizeof(int));
// run version with static shared memory
cudaMemcpy(d_d, a, n*sizeof(int), cudaMemcpyHostToDevice);
staticReverse<<<1,n>>>(d_d, n);
cudaMemcpy(d, d_d, n*sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i]) printf("Error: d[%d]!=r[%d] (%d, %d)n", i, i, d[i], r[i]);
}
The __syncthreads() is light weighted and a block level synchronization barrier. __syncthreads() ensures all threads have completed before continue.
Dynamic Shared Memory:
#include
__global__ void dynamicReverse(int *d, int n)
{
// Dynamic shared memory
extern __shared__ int s[];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
int main(void)
{
const int n = 64;
int a[n], r[n], d[n];
for (int i = 0; i < n; i++) {
a[i] = i;
r[i] = n-i-1;
d[i] = 0;
}
int *d_d;
cudaMalloc(&d_d, n * sizeof(int));
// run dynamic shared memory version
cudaMemcpy(d_d, a, n*sizeof(int), cudaMemcpyHostToDevice);
dynamicReverse<<<1,n,n*sizeof(int)>>>(d_d, n);
cudaMemcpy(d, d_d, n * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i]) printf("Error: d[%d]!=r[%d] (%d, %d)n", i, i, d[i], r[i]);
}
Shared memory are accessable by multiple threads. To reduce potential bottleneck, shared memory is divided into logical banks. Successive sections of memory are assigned to successive banks. Each bank services only one thread request at a time, multiple simultaneous accesses from different threads to the same bank result in a bank conflict (the accesses are serialized).
Shared memory banks are organized such that successive 32-bit words are assigned to successive banks and the bandwidth is 32 bits per bank per clock cycle. For devices of compute capability 1.x, the warp size is 32 threads and the number of banks is 16. There will be 2 requests for the warp: one for the first half and second for the second half. For devices of compute capability 2.0, the warp size is 32 threads and the number of banks is also 32. So for the best case, we need only 1 request.
For devices of compute capability 3.x, the bank size can be configured by cudaDeviceSetSharedMemConfig() to either four bytes (default) or eight bytes. 8-bytes avoids shared memory bank conflicts when accessing double precision data.
Share memory size configuration
On devices of compute capability 2.x and 3.x, each multiprocessor has 64KB of on-chip memory that can be partitioned between L1 cache and shared memory.
For devices of compute capability 2.x, there are two settings:
- 48KB shared memory and 16KB L1 cache, (default)
- and 16KB shared memory and 48KB L1 cache.
This can be configured during runtime API from the host for all kernels using cudaDeviceSetCacheConfig() or on a per-kernel basis using cudaFuncSetCacheConfig().
Constant memory
SM aggressively cache constant memory which results in short latency.
__constant__ float M[10];
...
cudaMemcpyToSymbol(...);
Blocks and threads
CUDA uses blocks and threads to provide data parallelism. CUDA creates multiple blocks and each block has multiple threads. Each thread calls the same kernel to process a section of the data.
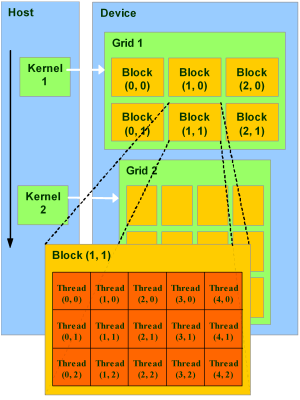
(source: Nvidia)
Here, we change our sample code to add 1024x1024 numbers together but the kernel remains almost the same by adding just one pair of number. To add all the numbers, we therefore create 4096 blocks with 256 threads per block.
\[\text{# of numbers} = (\text{# of blocks}) \times (\text{# threads/block}) \times (\text{# of additions in the kernel})\] \[1024 \times 1024 = 4096 \times 256 \times 1\]Each thread that executes the kernel is given a unique Bock ID & thread ID that is accessible within the kernel through the built-in blockIdx.x and threadIdx,x variable. We use this index to locate which pairs of number we want to add in the kernel.
\[index_{data} = index_{block} * \text{ (# of threads per block)} + index_{thread}\]__global__ void add(int *a, int *b, int *c)
{
// blockIdx.x is the index of the block.
// Each block has blockDim.x threads.
// threadIdx.x is the index of the thead.
// Each thread can perform 1 addition.
// a[index] & b[index] are the 2 numbers to add in the current thread.
int index = blockIdx.x * blockDim.x + threadIdx.x;
c[index] = a[index] + b[index];
}
We change the program to add 1024x1024 numbers together with 256 threads per block:
#define N (1024*1024)
#define THREADS_PER_BLOCK 256
int main(void) {
int *a, *b, *c;
// Alloc space for host copies of a, b, c and setup input values
a = (int *)malloc(size); random_ints(a, N);
b = (int *)malloc(size); random_ints(b, N);
c = (int *)malloc(size);
int *d_a, *d_b, *d_c;
int size = N * sizeof(int);
// Alloc space for device copies of a, b, c
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Copy inputs to device
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
// Launch add() kernel on GPU
add<<<N/THREADS_PER_BLOCK,THREADS_PER_BLOCK>>>(d_a, d_b, d_c);
// Copy result back to host
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
// Cleanup
free(a); free(b); free(c);
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}
Here we invoke the kernel with multiple blocks and multiple threads per block.
// Launch add() kernel on GPU
// Use N/THREADS_PER_BLOCK blocks and THREADS_PER_BLOCK threads per block
add<<<N/THREADS_PER_BLOCK,THREADS_PER_BLOCK>>>(d_a, d_b, d_c);
Threads & shared memory
Why do we need threads when we have blocks? CUDA threads have access to multiple memory spaces with different performance. Each thread has its own local memory. Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block. All threads have access to the same global memory. Data access for the shared memory is faster than the global memory. Data is copy from the host to the global memory in the GPU first. All threads in a block run on the same multiprocessor. Hence, to reduce memory latency, we can copy all the data needed for a block from the global memory to the shared memory.
Use __shared__ to declare a variable using the shared memory:
__global__ void add(int *a, int *b, int *c)
{
__shared__ int temp[1000];
}
Shared memory speeds up performance in particular when we need to access data frequently. Here, we create a new kernel stencil which add all its neighboring data within a radius.
\[out = in_{k-radius} + in_{k-radius+1} + \dots + in_{k} + in_{k+radius-1} + in_{k+radius}\]We read all data needed in a block to a shared memory. With a radius of 7 and a block with index from 512 to 1023, we need to read data from 505 to 1030.
#define RADIUS 7
#define BLOCK_SIZE 512
__global__ void stencil(int *in, int *out)
{
__shared__ int temp[BLOCK_SIZE + 2 * RADIUS];
int gindex = threadIdx.x + blockIdx.x * blockDim.x;
int lindex = threadIdx.x + RADIUS;
// Read input elements into shared memory
temp[lindex] = in[gindex];
// At both end of a block, the sliding window moves beyond the block boundary.
// E.g, for thread id = 512, we wiil read in[505] and in[1030] into temp.
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
// Apply the stencil
int result = 0;
for (int offset = -RADIUS ; offset <= RADIUS ; offset++)
result += temp[lindex + offset];
// Store the result
out[gindex] = result;
}
We must make sure the shared memory is smaller than the available physical shared memory.
Thread synchronization
The code in the last section has a fatal data racing problem. Data is not stored in the shared memory before accessing it. For example, to compute the result for say thread 20, we need to access \(temp\) corresponding to \(in[13]\) to \(in[27]\).
for (int offset = -RADIUS ; offset <= RADIUS ; offset++)
result += temp[lindex + offset]; // Data race problem here.
However, thread 27 is responsible for loading \(temp\) with \(in[27]\). Since threads are executed in parallel with no guarantee of order, we may compute the result for thread 20 before thread 27 stores \(in[27]\) into \(temp\).
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
So, like other multi-threading programming, CUDA provides thread synchronization methods __syncthreads to solve this data racing problem. All threads will be blocked at __syncthreads until all threads in the same block have reached the same point.
__global__ void stencil_1d(int *in, int *out) {
__shared__ int temp[BLOCK_SIZE + 2 * RADIUS];
int gindex = threadIdx.x + blockIdx.x * blockDim.x;
int lindex = threadIdx.x + RADIUS;
// Read input elements into shared memory
temp[lindex] = in[gindex];
// At both end of a block, the sliding window moves beyond the block boundary.
if (threadIdx.x < RADIUS) {
temp[lindex - RADIUS] = in[gindex - RADIUS];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
// Synchronize (ensure all the threads will be completed before continue)
__syncthreads();
// Apply the stencil
int result = 0;
for (int offset = -RADIUS ; offset <= RADIUS ; offset++)
result += temp[lindex + offset];
// Store the result
out[gindex] = result;
}
__syncthreads is expected to be lightweight.
Other synchronization methods:
| Call | Behavior |
|---|---|
| cudaMemcpy() | Blocks the CPU until the copy is complete Copy begins when all preceding CUDA calls have completed |
| cudaMemcpyAsync() | Asynchronous, does not block the CPU |
| cudaDeviceSynchronize() | Blocks the CPU until all preceding CUDA calls have completed |
Thread hierarchy
In pervious example, the thread index \(threadIdx.x\) is 1-dimensional. To access multiple dimensional matrices easier, CUDA also support multiple dimensional thread index.
The following code add two 2-D matrices with 1 thread block of NxN threads. \(threadIdx.x\) and \(threadIdx.y\) represents a 2-dimensional index for easy 2-D matrix access.
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
// the blockIdx and treadIdx is now 2-dimensional.
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
dim3 threadsPerBlock(N, N);
MatAdd<<<1, threadsPerBlock>>>(A, B, C);
...
}
CUDA supports one-dimensional, two-dimensional, or three-dimensional thread index with the type \(dim3\).
A block may not align exactly with the input data boundary. We add a if loop to avoid a thread to go beyond the input data boundary. For example, in the last block, we may not have enough data for the amount of threads configured.
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
// Avoid a thread block that go beyond the input data boundary.
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
A thread block size of 16x16 (256 threads) is a very common choice.
nvcc
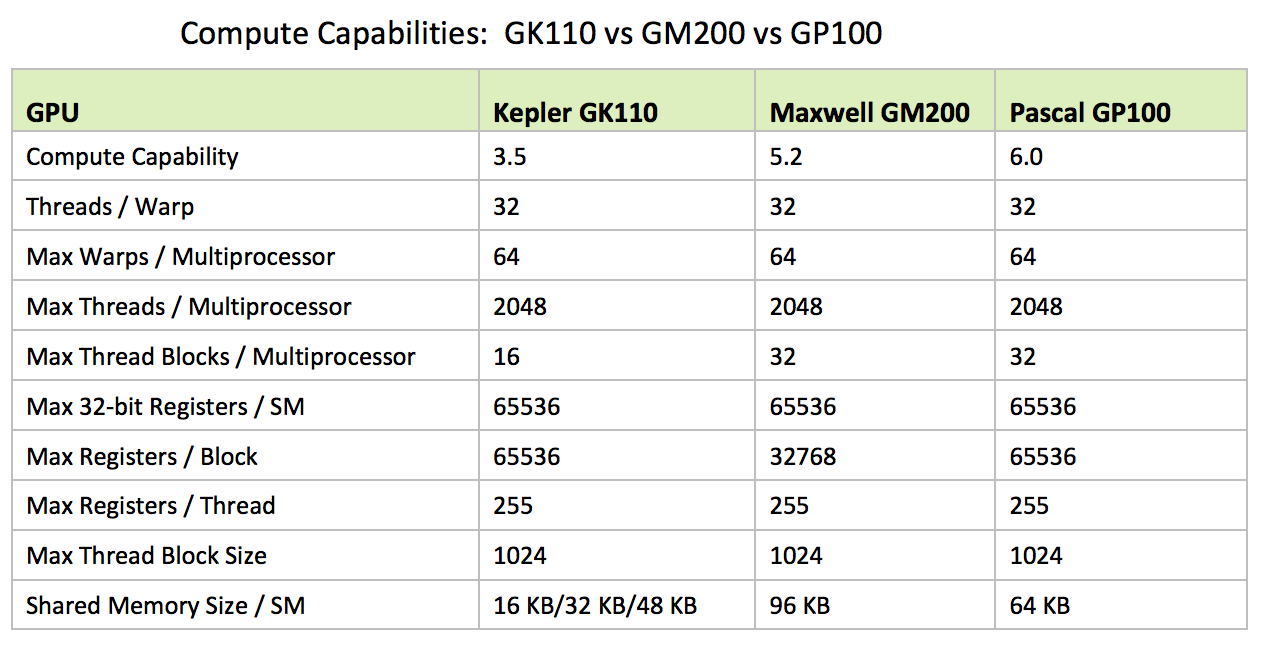
The compute capability of a device “SM version” shows what a device supports. We can compile code to support multiple target devices:
nvcc x.cu -gencode arch=compute_20,code=sm_20
-gencode arch=compute_30,code=sm_30
-gencode arch=compute_35,code=\'compute_35,sm_35\'
“arch=compute_20,code=sm_20” instructs the compiler to generate binary code for devices of compute capability 2.0.
This embeds binary code compatible with compute capability 2.0 and 3.0 and PTX and binary code compatible with compute capability 3.5 (third -gencode option). Host code will select at runtime the most appropriate code to load and execute for the target device.
PTU is the CUDA instruction set. Any PTX code is compiled further to binary code by the device driver (by a just-in-time compiler). This takes advantage of future versions of hardware.
The runtime for CUDA calls is implemented in the cudart library, which is linked to the application, either statically via cudart.lib or libcudart.a, or dynamically via cudart.dll or libcudart.so. Those libraries are included during installation.
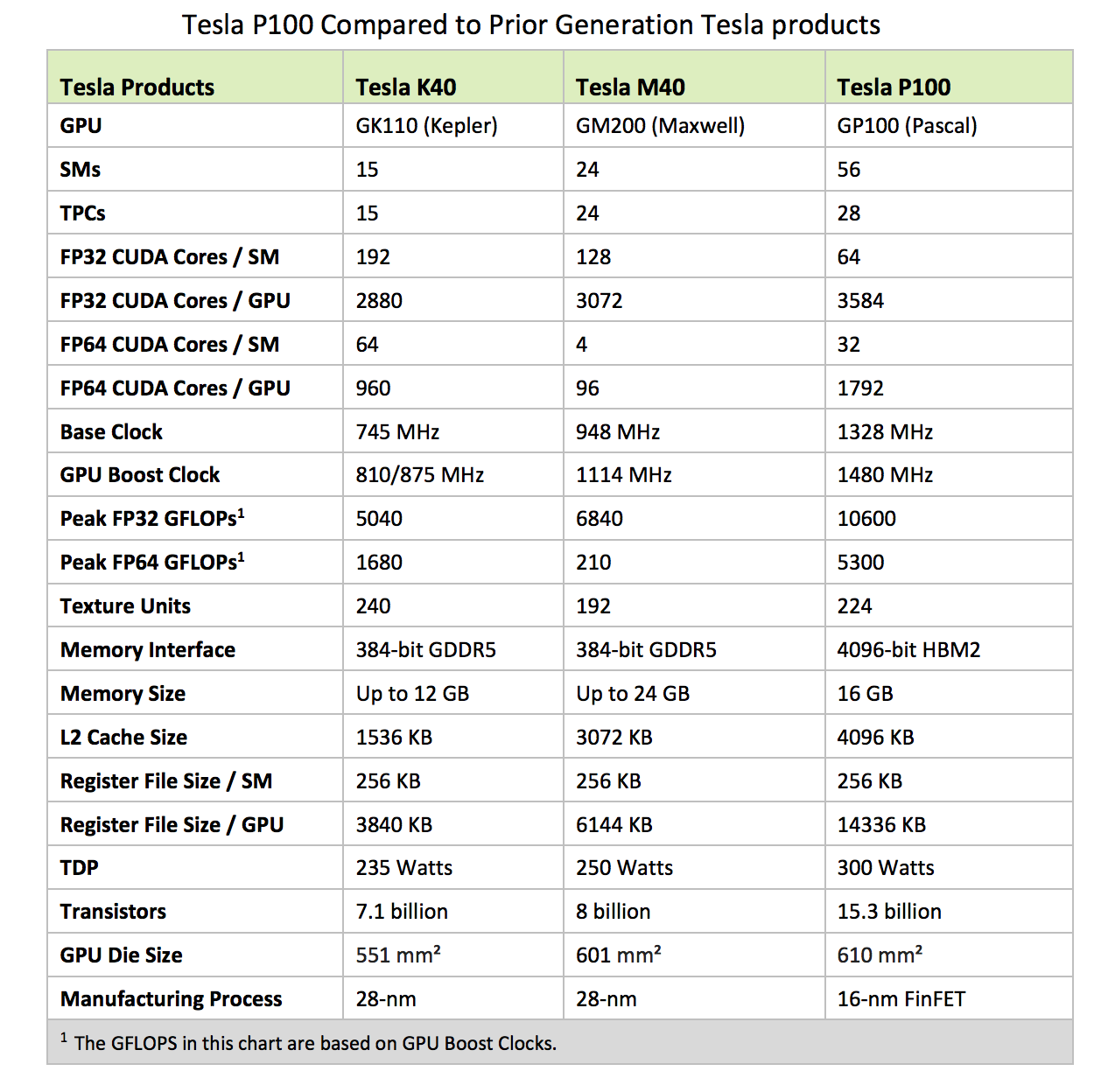
Nvidia Tesla P100
Let’s take a glimpse of the product offering for GPGPU cards. (General purpose GPU). The followings are the Nvidia Tesla P100 GPGPU cards with the Pascal GP100 GPU in the middle and memory (DRAM) on the sides:
Images from this section are from Nvidia

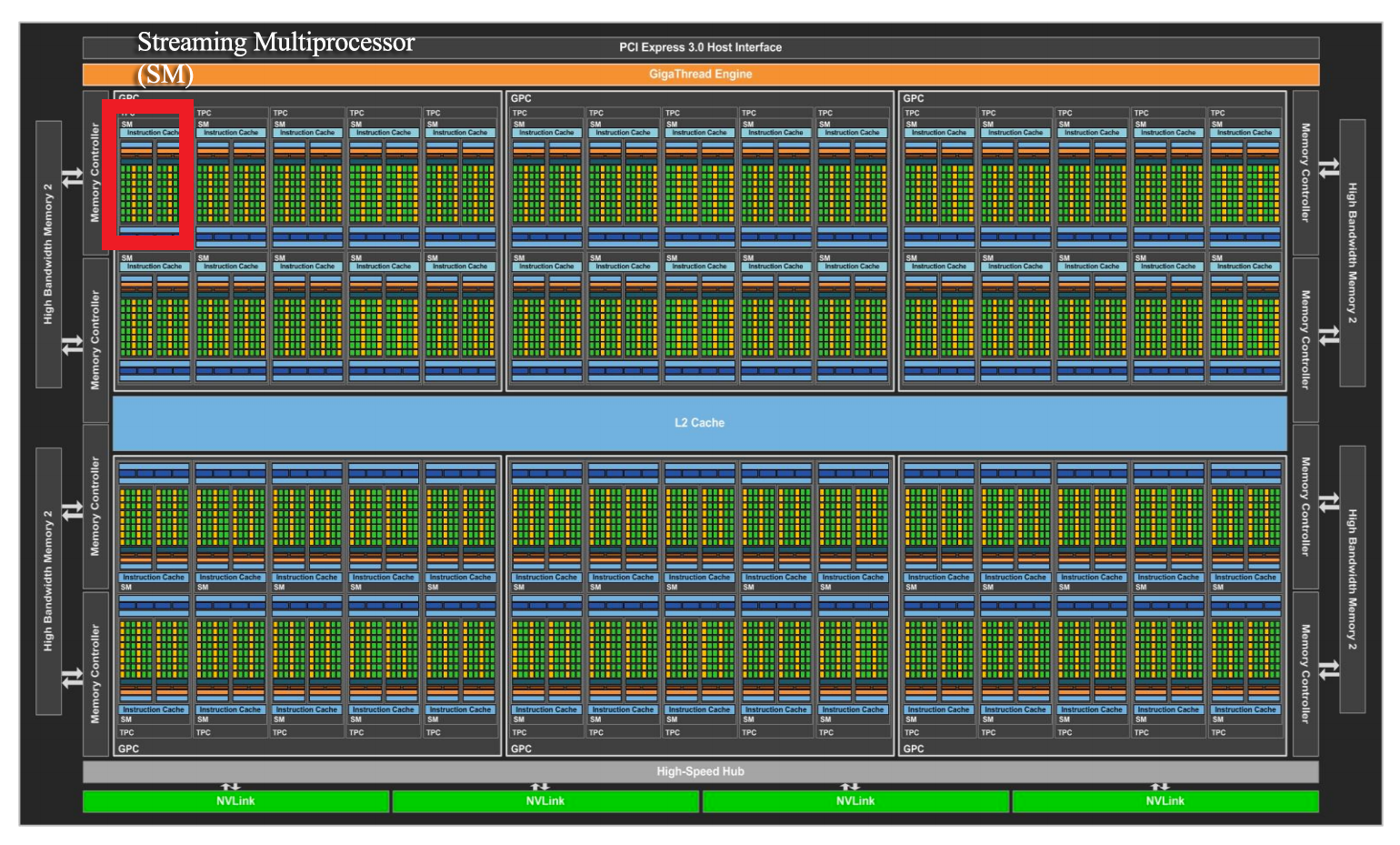
Pascal GP100 GPU with 60 Streaming Multiprocessors (SM) Units
GP100 contains 6 Graphics Processing Clusters (GPCs), 30 Texture Processing Clusters (TPCs) and eight 512-bit memory controllers (4096 bits total). Each GPC has 10 SMs (a total of 60 SMs). Each SM has 64 CUDA Cores and four texture units. With 60 SMs, GP100 has a total of 3840 single precision CUDA Cores and 240 texture units. Each memory controller is attached to 512 KB of L2 cache, and each HBM2 DRAM stack is controlled by a pair of memory controllers. The full GPU includes a total of 4096 KB of L2 cache.
Pascal is the Nvidia GPU architecture as the successor to the Maxwell which precede Kepler .
The following is the device query information for Tesla P100:
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla P100-PCIE-16GB"
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 6.0
Total amount of global memory: 16276 MBytes (17066885120 bytes)
(56) Multiprocessors, ( 64) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 405 MHz (0.41 GHz)
Memory Clock rate: 715 Mhz
Memory Bus Width: 4096-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = Tesla P100-PCIE-16GB
Result = PASS
To maximize performance and data parallelism, we need to fully aware of the memory size for different memory structures, number of cores per SM and maximum thread size. We want to have the maximum parallelism within the physical capacity of the GPU.
Call cudaGetDeviceProperties to get the device information from an application.
Streaming Multiprocessor

GP100’s SM has 64 single-precision (FP32) CUDA Cores. The GP100 SM is partitioned into two processing blocks, each having 32 single-precision CUDA Cores, an instruction buffer, a warp scheduler, and two dispatch units.
L1/L2 cache
Kepler GPUs featured a 64 KB configurable shared memory and L1 cache that could split the allocation of memory between L1 and shared memory functions depending on workload. Beginning with Maxwell, the cache hierarchy was changed. The GP100 SM has its own dedicated pool of shared memory (64 KB/SM) and an L1 cache that can also serve as a texture cache depending on workload. The unified L1/texture cache acts as a coalescing buffer for memory accesses, gathering up the data requested by the threads of a warp prior to delivery of that data to the warp. GP100 features a unified 4096 KB L2 cache that provides efficient, high speed data sharing across the GPU. With more cache located on-chip, fewer requests to the GPU’s DRAM are needed.
Memory
Device memory (Global memory)
Device memory can be allocated either as linear memory. Like our sample code before, linear memory is managed by cudaMalloc, cudaFree and cudaMemcpy. Linear memory can also be managed by cudaMalloc3D, cudaMemcpy2D and cudaMemcpy3D for 2D or 3D arrays.
For 2-D array:
// Host code
int width = 64, height = 64;
float* devPtr;
size_t pitch;
cudaMallocPitch(&devPtr, &pitch, width * sizeof(float), height);
MyKernel<<<100, 512>>>(devPtr, pitch, width, height);
// Device code __global__ void MyKernel(float* devPtr, size_t pitch, int width, int height)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}
For a 3-D array:
// Host code
int width = 64, height = 64, depth = 64;
cudaExtent extent = make_cudaExtent(width * sizeof(float), height, depth);
cudaPitchedPtr devPitchedPtr;
cudaMalloc3D(&devPitchedPtr, extent);
MyKernel<<<100, 512>>>(devPitchedPtr, width, height, depth);
// Device code __global__ void MyKernel(cudaPitchedPtr devPitchedPtr, int width, int height, int depth)
{
char* devPtr = devPitchedPtr.ptr;
size_t pitch = devPitchedPtr.pitch;
size_t slicePitch = pitch * height;
for (int z = 0; z < depth; ++z) {
char* slice = devPtr + z * slicePitch;
for (int y = 0; y < height; ++y) {
float* row = (float*)(slice + y * pitch);
for (int x = 0; x < width; ++x) {
float element = row[x];
}
}
}
}
Other ways to copy memory:
__constant__ float constData[256];
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));
cudaMemcpyFromSymbol(data, constData, sizeof(data));
__device__ float devData;
float value = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
__device__ float* devPointer;
float* ptr;
cudaMalloc(&ptr, 256 * sizeof(float));
cudaMemcpyToSymbol(devPointer, &ptr, sizeof(ptr));
Pitch
Memory access is most efficient if aligned correctly. Mis-aligned access requires extra memory load. cudaMallocPitch & cudaMemcpy2D takes care of necessary memory padding for memory alignement for 2-D arrays.
Shared memory
Shared memory is expected to be much faster than global memory and declared with __shared__.
source Nvidia (CUDA tookit documentation)
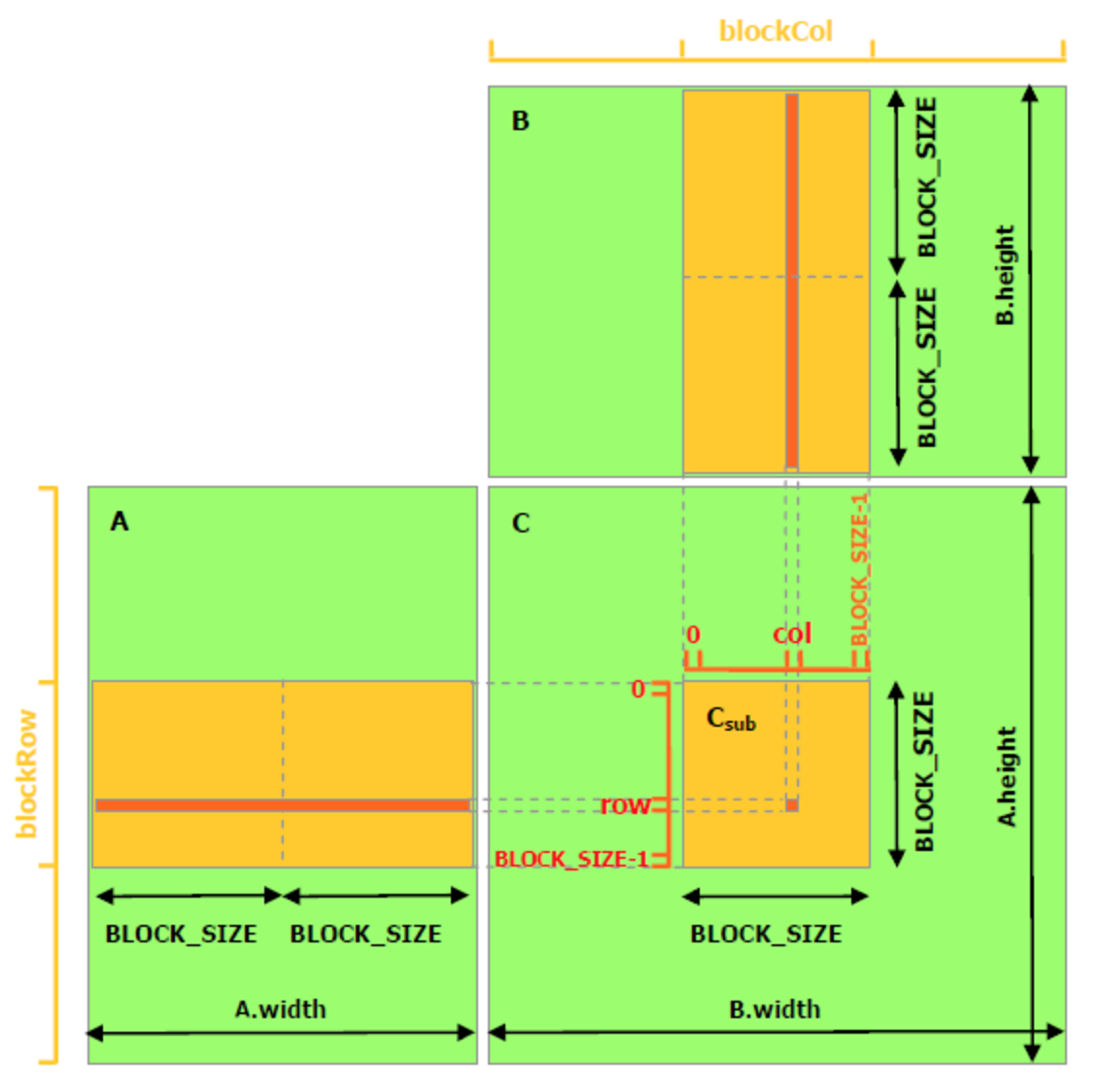
Matrix multiplication with shared memory
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.stride + col)
typedef struct {
int width;
int height;
int stride;
float* elements;
} Matrix;
// Get a matrix element
__device__ float GetElement(const Matrix A, int row, int col)
{
return A.elements[row * A.stride + col];
}
// Set a matrix element
__device__ void SetElement(Matrix A, int row, int col,
float value)
{
A.elements[row * A.stride + col] = value;
}
// Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is
// located col sub-matrices to the right and row sub-matrices down
// from the upper-left corner of A
__device__ Matrix GetSubMatrix(Matrix A, int row, int col)
{
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row
+ BLOCK_SIZE * col];
return Asub;
}
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory
Matrix d_A;
d_A.width = d_A.stride = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size,
cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = d_B.stride = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,
cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = d_C.stride = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
// Read C from device memory
cudaMemcpy(C.elements, d_C.elements, size,
cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
// Matrix multiplication kernel called by MatMul()
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
{
// Block row and column
int blockRow = blockIdx.y;
int blockCol = blockIdx.x;
// Each thread block computes one sub-matrix Csub of C
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
// Each thread computes one element of Csub
// by accumulating results into Cvalue
float Cvalue = 0;
// Thread row and column within Csub
int row = threadIdx.y;
int col = threadIdx.x;
// Loop over all the sub-matrices of A and B that are
// required to compute Csub
// Multiply each pair of sub-matrices together
// and accumulate the results
for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
// Get sub-matrix Asub of A
Matrix Asub = GetSubMatrix(A, blockRow, m);
// Get sub-matrix Bsub of B
Matrix Bsub = GetSubMatrix(B, m, blockCol);
// Shared memory used to store Asub and Bsub respectively
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load Asub and Bsub from device memory to shared memory
// Each thread loads one element of each sub-matrix
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
// Synchronize to make sure the sub-matrices are loaded
// before starting the computation
__syncthreads();
// Multiply Asub and Bsub together
for (int e = 0; e < BLOCK_SIZE; ++e)
Cvalue += As[row][e] * Bs[e][col];
// Synchronize to make sure that the preceding
// computation is done before loading two new
// sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write Csub to device memory
// Each thread writes one element
SetElement(Csub, row, col, Cvalue);
}
Shared memory is divided into equally sized memory modules called banks. Banks can be accessed concurrently. Shared memory accesses in consecutive locations can therefore loaded simultaneously.
Dynamic shared memory
Use dynamic shared memory if the size of the array is not known inside the kernel:
{
extern __shared__ int array[];
}
Supply the size when launching the kernel:
add<<<10, 10, N*sizeof(int)>>>(d_a, d_b);
Page-Locked Host Memory
Unified Virtual Addressing (UVA) in CUDA 4 provides a single virtual memory address space for both CPU and GPU memory and enable pointers to be accessed from GPU code. UVA enables Zero-copy memory, which is pinned CPU memory accessible by GPU code directly over PCIe, without a memcpy. Zero-Copy provides some of the convenience of Unified Memory (described in later section which do implicit memory copy). Both mechanisms release the burden of programmers to manage memory transfer explicitly. Zero-copy is good for the kernel code accessing host data sparsely or not repeatedly. In contrast to Unified Memory, data is always accessed by the GPU with PCIe’s low bandwidth and high latency. Unified memory provide faster memory access if same data is read repeatedly.
Instead of using malloc in allocating host memory, we call CUDA to create page-locked pinned host memory. Page-locked host memory has several benefits:
- Asynchronous concurrent execution of kernels and memory transfer using streaming.
- With mapped memory, it eliminates the need of allocate a block in device memory.
- Higher bandwidth between host and device memory in particular with Write-combining memory.
Page-locked host memory is managed by:
- cudaHostAlloc and cudaFreeHost allocate and free page-locked host memory.
- cudaHostRegister page-locks memory allocated by malloc
Page-lock host memory disturb how a system manage memory . Will have catastrophic result if memory is running low.
Tips:
- Portable memory: Set the flag cudaHostAllocPortable in cudaHostAlloc or cudaHostRegisterPortable in cudaHostRegister. This make the block (memory block) available to all devices, not just the device that was current when the memory was allocated.
- Write-Combining Memory: Set the flag cudaHostAllocWriteCombined in cudaHostAlloc. Write-combining memory frees up the host’s L1 and L2 cache resources which is not needed and will improve transfer performance to the device by up to 40%.
- Reading from write-combining memory from the host is prohibitively slow, so write-combining memory should be used for memory that the host only writes to.
Mapped memory
If a device support mapped memory, we can use mapped memory by enable cudaDeviceMapHost in cudaSetDeviceFlags once, and then allocate the memory with the flag cudaHostAllocMapped in cudaHostAlloc or cudaHostRegisterMapped in cudaHostRegister. A block of page-locked host memory can be mapped into the address space of the device. The memory block has two addresses: one in host memory that is returned by cudaHostAlloc, and one in device memory that can be retrieved using cudaHostGetDevicePointer. Mapped memory allow a kernel to access a host memory directly. Data transfers are implicitly performed as needed by the kernel. Therefore, data transfer can also be concurrent with Kernel execution without a stream.
Since mapped memory is shared between host and device, the application must synchronize memory accesses using streams or events between host and device.
void sortfile(FILE *fp, int N)
{
...
qsort<<<...>>>(data, N, 1, compare);
cudaDevicesSynchronize();
use_data(data);
cudaFree(data);
}
To retrieve the device pointer of a mapped memory, memory mapping must be enabled by setting cudaDeviceMapHost in cudaSetDeviceFlags.
Unified Memory
Pascal GP100 GPU architecture adds new feature to the Unified Memory. It defines a single memory space accessing from CPU and GPU. Programmers no longer need to manage data transfer between the host and device memory. Unified Memory creates a pool of managed memory that is shared between the CPU and GPU. Managed memory is accessible to both the CPU and GPU using a single pointer. GP100 supports hardware page faulting, and allows transparent migration of data between the full virtual address spaces of both the GPU and CPU. If a kernel running on the GPU accesses a page that is not in its GPU memory, it faults. It allows the page to be automatically migrated to the GPU memory on-demand.
Unified Memory eliminates the need for explicit data transfer. Data transfer still occurs but a copy will preside in the GPU such that it will not suffer performance penalty like the zero-copy when it is accessed multiple times. Zero-copy allocations pinned the memory in the CPU system such that a program may have fast or slow access to it depending on where it is being accessed from. Unified Memory, on the other hand, decouples memory and execution spaces so that all data accesses are fast.
By default starting with CUDA 8.0 with compute capability 6, malloc or new can be accessed from both GPU and CPU. Unified Memory is the default:
The Unified memory code can also use __managed__ to declare variables. No cudaMemcpy is needed. cudaMemcpy will synchronize kernel calls with memory transfer. In Unified memory, we use cudaDeviceSynchronize for such synchronization.
__device__ __managed__ int ret[1000];
__global__ void AplusB(int a, int b) {
ret[threadIdx.x] = a + b + threadIdx.x;
}
int main() {
AplusB<<< 1, 1000 >>>(10, 100);
cudaDeviceSynchronize(); // Since data transfer is on demand, we need to syncronize the code here before printing the result.
for(int i=0; i<1000; i++)
printf("%d: A+B = %d\n", i, ret[i]);
return 0;
}
Alloc it manually with cudaMallocManaged:
__global__ void printme(char *str) {
printf(str);
}
int main() {
// Allocate 100 bytes of memory, accessible to both Host and Device code
char *s;
cudaMallocManaged(&s, 100);
// Note direct Host-code use of "s"
strncpy(s, "Hello Unified Memory\n", 99);
// Here we pass "s" to a kernel without explicitly copying
printme<<< 1, 1 >>>(s);
cudaDeviceSynchronize();
// Free as for normal CUDA allocations
cudaFree(s);
return 0;
}
By migrating data on demand between the CPU and GPU, Unified Memory can offer the performance of local data on the GPU. With page faulting on GP100, locality can be ensured even for programs with sparse data access, where the pages accessed by the CPU or GPU cannot be known ahead of time, and where the CPU and GPU access parts of the same array allocations simultaneously.
CUDA 8 introduce APIs for providing hints to the runtime with memory usage and for explicit prefetching. These tools allow the same capabilities as explicit memory copy and pinning APIs, without reverting to the limitations of explicit GPU memory allocation.
Pre-6x compute capability
For GPU in pre-6x compute capability, GPU has exclusive access to all managed data while any kernel operation is executing, regardless of whether the specific kernel is actively using the data.
__device__ __managed__ int x, y=2;
__global__ void kernel() {
x = 10;
}
int main() {
kernel<<< 1, 1 >>>();
y = 20; // Error on GPUs not supporting concurrent access
cudaDeviceSynchronize();
return 0;
}
The code runs successfully for compute capability >= 6.x. However, fail otherwise, even y is not read by the kernel.
To fix it for those devices,
__device__ __managed__ int x, y=2;
__global__ void kernel() {
x = 10;
}
int main() {
kernel<<< 1, 1 >>>();
cudaDeviceSynchronize();
y = 20; // Success on GPUs not supporing concurrent access
return 0;
}
Here, we allow y to attach to the host and accessible by the host at all time.
__device__ __managed__ int x, y=2;
__global__ void kernel() {
x = 10;
}
int main() {
cudaStream_t stream1;
cudaStreamCreate(&stream1);
cudaStreamAttachMemAsync(stream1, &y, 0, cudaMemAttachHost);
cudaDeviceSynchronize(); // Wait for Host attachment to occur.
kernel<<< 1, 1, 0, stream1 >>>(); // Note: Launches into stream1.
y = 20; // Success – a kernel is running but “y”
// has been associated with no stream.
return 0;
}
cudaStreamAttachMemAsync associates ptr with the specified stream. The Unified Memory allows CPU access to ptr so long as all operations in stream have completed, regardless of other streams.
Asynchronous Concurrent Execution
Asynchronous calls return back to host thread before finishing the requests. These calls are:
- Kernel launches.
- Memory copies between two addresses to the same device memory.
- Memory copies from host to device of a memory block of 64 KB or less.
- Memory copies performed by functions with the Async suffix.
- Memory set function calls.
Streams
Kernels can be executed in parallel with streams. A stream is a sequence of commands (possibly from host threads) that execute in sequence. Different streams, on the other hand, may execute their commands concurrently. Kernels launched into the same stream are guaranteed to execute consecutively, while kernels launched into different streams are permitted to execute concurrently.
For example, we can create 3 streams each one handle a sequence of 3 depending tasks. Each stream can run in parallel:

Streams
cudaStream_t stream[3];
for (int i = 0; i < 3; ++i)
cudaStreamCreate(&stream[i]);
float* hostPtr;
cudaMallocHost(&hostPtr, 3 * size);
If it is not a Unified memory, hostPtr must point to page-locked host memory for any concurrent process here.
To execute streams:
for (int i = 0; i < 3; ++i) {
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel <<<100, 512, 0, stream[i]>>>
(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
cudaMemcpyAsync allows concurrent memory transfer in different streams.
If launching a kernel without specific a stream, the default stream 0 is used.
To destroy streams:
for (int i = 0; i < 2; ++i)
cudaStreamDestroy(stream[i]);
If the stream is not defined, the default stream 0 will be used.
Streams with Unified memory
Stream synchronization
cudaDeviceSynchronize waits until all preceding commands in all streams of all host threads have completed. cudaStreamSynchronize waits for a particular stream instead of all streams.
Stream priority
Setting stream priority:
// get the range of stream priorities for this device
int priority_high, priority_low;
cudaDeviceGetStreamPriorityRange(&priority_low, &priority_high);
// create streams with highest and lowest available priorities
cudaStream_t st_high, st_low;
cudaStreamCreateWithPriority(&st_high, cudaStreamNonBlocking, priority_high);
cudaStreamCreateWithPriority(&st_low, cudaStreamNonBlocking, priority_low);
Events
Application can asynchronously record events at any point in the program for monitor the device progress.
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
...
cudaEventRecord(start, 0);
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>
(outputDev + i * size, inputDev + i * size, size);
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
...
cudaEventDestroy(start);
cudaEventDestroy(stop);
Multiple GPUs
To get and set different GPU to launch kernels:
int numDevs= 0;
cudaGetDeviceCount(&numDevs);
for (int d = 0; d < numDevs; d++) {
cudaSetDevice(d);
kernel<<<blocks, threads>>>(args);
}
Peer to peer access
Use cudaDeviceCanAccessPeer to verify device capability and cudaDeviceEnablePeerAccess to enable peer access. cudaMemcpyPeer for peer to peer copy.
cudaSetDevice(0); // Set device 0 as current
float* p0;
size_t size = 1024 * sizeof(float);
cudaMalloc(&p0, size); // Allocate memory on device 0
MyKernel<<<1000, 128>>>(p0); // Launch kernel on device 0
cudaSetDevice(1); // Set device 1 as current
cudaDeviceEnablePeerAccess(0, 0); // Enable peer-to-peer access
// with device 0
// Launch kernel on device 1
// This kernel launch can access memory on device 0 at address p0
MyKernel<<<1000, 128>>>(p0);
Dynamic parallelism
Kernels can start new kernels, and streams can spawn new streams. To make sure all child kernels are completed, use cudaDeviceSynchronize.
__global__ void child_launch(int *data) {
data[threadIdx.x] = data[threadIdx.x]+1;
}
__global__ void parent_launch(int *data) {
data[threadIdx.x] = threadIdx.x;
__syncthreads();
if (threadIdx.x == 0) {
child_launch<<< 1, 256 >>>(data);
cudaDeviceSynchronize();
}
__syncthreads();
}
void host_launch(int *data) {
parent_launch<<< 1, 256 >>>(data);
}
Texture memory
Texture memory is a read-only memory for spatial data. It is cached in SM’s texture caches. For spatial data, texture memory is more effective comparing with global memory.
Apply some simple transformation kernel to a texture.
// Simple transformation kernel
__global__ void transformKernel(float* output,
cudaTextureObject_t texObj,
int width, int height,
float theta)
{
// Calculate normalized texture coordinates
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
float u = x / (float)width;
float v = y / (float)height;
// Transform coordinates
u -= 0.5f;
v -= 0.5f;
float tu = u * cosf(theta) - v * sinf(theta) + 0.5f;
float tv = v * cosf(theta) + u * sinf(theta) + 0.5f;
// Read from texture and write to global memory
output[y * width + x] = tex2D<float>(texObj, tu, tv);
}
// Host code
int main()
{
// Allocate CUDA array in device memory
cudaChannelFormatDesc channelDesc =
cudaCreateChannelDesc(32, 0, 0, 0,
cudaChannelFormatKindFloat);
cudaArray* cuArray;
cudaMallocArray(&cuArray, &channelDesc, width, height);
// Copy to device memory some data located at address h_data
// in host memory
cudaMemcpyToArray(cuArray, 0, 0, h_data, size,
cudaMemcpyHostToDevice);
// Specify texture
struct cudaResourceDesc resDesc;
memset(&resDesc, 0, sizeof(resDesc));
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array.array = cuArray;
// Specify texture object parameters
struct cudaTextureDesc texDesc;
memset(&texDesc, 0, sizeof(texDesc));
texDesc.addressMode[0] = cudaAddressModeWrap;
texDesc.addressMode[1] = cudaAddressModeWrap;
texDesc.filterMode = cudaFilterModeLinear;
texDesc.readMode = cudaReadModeElementType;
texDesc.normalizedCoords = 1;
// Create texture object
cudaTextureObject_t texObj = 0;
cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL);
// Allocate result of transformation in device memory
float* output;
cudaMalloc(&output, width * height * sizeof(float));
// Invoke kernel
dim3 dimBlock(16, 16);
dim3 dimGrid((width + dimBlock.x - 1) / dimBlock.x,
(height + dimBlock.y - 1) / dimBlock.y);
transformKernel<<<dimGrid, dimBlock>>>(output,
texObj, width, height,
angle);
// Destroy texture object
cudaDestroyTextureObject(texObj);
// Free device memory
cudaFreeArray(cuArray);
cudaFree(output);
return 0;
}
Error handling
parentKernel<<<1,1>>>();
if (cudaSuccess != cudaGetLastError())
{
return 1;
}
Use _ cudaGetErrorString_ to retrieve the error message.
Optimization
Maximize utilization & parallelism
- Use streaming and asynchronous functions calls to maximize kernel concurrency.
- Use as many SM as possible.
- If thread synchronization is required to write shared data before reading it, use block level synchronization with __syncthreads over breaking the kernel into 2 synchronized kernels: one for write and the other for read.
- Structure the design such that synchronization is done at block level rather than at kernel level.
SM level utilization & parallelism: The number of threads per block is important. When SM executes an instruction \(i_{k}\) for a warp, the next instruction \(i_{k+1}\) of that warp may not be ready for execution for some number of clock cycles (called latency). Such latency may range from 11 clock cycles for the instruction \(i_{k}\) to complete (instructions are pipelined so we can start another instruction in a different warp without waiting \(i_{k}\) to complete) or 200-400 clock cycles if SM need to read global memory for the input operand of \(i_{k+1}\). To keep the SM busy. the warp scheduler will schedule another warp for execution. We call this latency hiding. High number of resident warps allows the warp scheduler to fully utilize the SM. However, registers will not be released until a thread is finished. Likewise, share memory has a lifecycle of a block. Hence, we need to make sure the resident warps do not consume more registers/memory than a SM can offer. To maximize utilization, we need to make sure we have a high number of resident warps with the constraints of registers/memory consumption. The size of the block threads impacts the number of resident warps. For example, if a thread needs 32 register, and if GPU assigns 2 blocks of 512 threads/block to a SM, it will need 322512 registers. If we need one more register per thread, they will push the count to 332512 which is higher than what a SM can offer (register spilling). This forces the compiler to use local memory which will degrade the performance.
The number of threads per block should be a multiple of the warp size to maximize utilization.
cudaOccupancyMaxActiveBlocksPerMultiprocessor provides an occupancy prediction based on the block size and shared memory usage of a kernel. This function reports occupancy in terms of the number of concurrent thread blocks per multiprocessor.
The code below calculates the ratio between concurrent warps versus maximum warps per multiprocessor.
// Device code
__global__ void MyKernel(int *d, int *a, int *b)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
d[idx] = a[idx] * b[idx];
}
// Host code
int main()
{
int numBlocks; // Occupancy in terms of active blocks
int blockSize = 32;
// These variables are used to convert occupancy to warps
int device;
cudaDeviceProp prop;
int activeWarps;
int maxWarps;
cudaGetDevice(&device);
cudaGetDeviceProperties(&prop, device);
cudaOccupancyMaxActiveBlocksPerMultiprocessor(
&numBlocks,
MyKernel,
blockSize,
0);
activeWarps = numBlocks * blockSize / prop.warpSize;
maxWarps = prop.maxThreadsPerMultiProcessor / prop.warpSize;
std::cout << "Occupancy: " << (double)activeWarps / maxWarps * 100 << "%" << std::endl;
return 0;
}
Maximize memory throughput
Objective: Minimize data transfer between the host & device, data transfer between the global memory & device.
Sorted by the memory latency (shortest on top):
| Registers | read/write | on-chip | by compiler |
| Shared memory | read/write | on-chip | user-managed cache |
| L1/texture/constant cache | on-chip | hardware managed cache | |
| L2 cache | on-chip | hardware managed cache | |
| Texture memory | read | on device | user program |
| Constant memory | read | on device | user program |
| Local memory | read/write | on device | |
| Global memory | read/write | on device |
Use of shared memory:
- Shared memory is much faster than local memory or global memory.
- Shared memory is divided into equally-sized modules, called banks which can be accessed concurrently. Design application access to avoid access the same bank simultaneously. (Avoid bank conflict.)
Shared memory usage pattern:
- Load data from device memory to shared memory.
- Synchronize with all the threads of the block so data is already populated by different threads.
- Process the data in shared memory by threads of the block.
- Synchronize again if necessary to make sure that shared memory has been updated with the results.
- Write the results back to device memory.
Host and device memory transfer:
- Move code (even with low parallelism) from the host to the device if it can avoid data transfer.
- Consolidate small transfers into a larger transfer.
- Page-locked host memory can speed up transfer if memory resource is not scare.
- Mapped memory by-passes explicit memory copy, it improve performance if data access is sparse or not repeating.
Memory access within a warp:
- When a warp executes an instruction, it coalesces all memory access to form the minimum memory loads.
- Design the application to localize/minimize memory accesses within a warp.
- Mis-aligned memory accesses require extra memory loading. Make sure memory access are aligned within a warp.
- For a 2D array access, make sure the width of the thread block and the array is a multiple of the warp size.
- Pad a 2D array using cudaMallocPitch and cuMemAllocPitch if needed.
Local memory:
- Local memory is actually stored in global memory. (same latency as global memory)
- Local memory is very slow comparing with shared memory.
- Compiler tries to place variables into registers except:
- Arrays that is not accessed with constant quantities, or
- Large structures or arrays that consume too much or cannot fit into the register space.
- Use cuobjdump to identify local memory, or –ptxas-options=-v during compilation for local memory size.
Constant/texture/surface memory:
- Stored in the device memory but can be cached for future hits.
- The texture cache is optimized for 2D spatial locality, and it is designed for streaming fetches with a constant latency.
Maximize instruction throughput
- Trade precision (single precision vs double precision) for speed if acceptable.
- Trade intrinsic functions vs regular functions if acceptable.
- Avoids arithmetic instructions with low throughput.
- Use compiler to unroll loop implicitly.
- Use #pragma unroll to explicitly unroll loops.
- Use compiler flags to generate faster but less precise code:
- “Denormalized numbers are flushed to zero” when compiling code gives better throughput.
- Other flags controlling precision.
Threads in a warp can diverge to different part of the code based on the conditions in the branching.
if (a[index]>=0)
a[index]++; // Branch 1
else
a[index]--; // Branch 2
In the example above, a thread in a warp may branch differently. If this happens, the different executions paths have to be serialized. Design the branch condition such that the code within a warp branches in the same way. Avoid threads within a warp (threadIdx / warpSize) following different execution paths.
C language extension
| Extension | meaning |
| __device__ | code executed in a device and callable only from a device |
| __host__ | code executed in a host and callable only from a host |
| __global__ | a kernel |
Variable extension
| __device__ | use with other declaration for memory space in a device |
| __constant__ | in constant space |
| __shared__ | in share space |
| __managed__ | Seen from both host and device. Implicit managed by GPU for data transfer |
| extern __shared__ | in share space with size passed from the host |
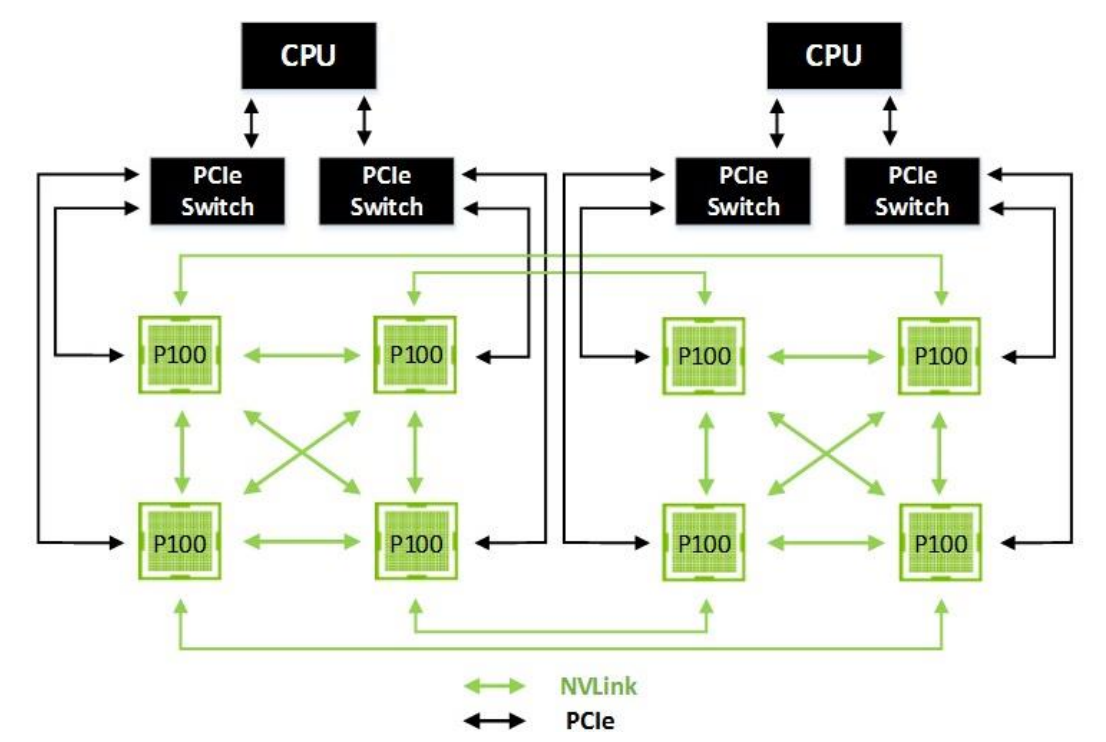
NVLink
NVLink improves both GPU-to-GPU communications and for GPU access to system memory.
Compute Preemption
Compute Preemption is another new feature of the Pascal GP100 GPU architecture. It allows tasks to be preempted at instruction-level with context swapped to device memory rather than interrupted at the thread block level as in prior Maxwell/Kepler GPU architectures. Compute Preemption prevents long-running applications from either monopolizing the system computation power or being time out or killed. Programmers no longer need to change their long-running applications to play nicely with other GPU applications. With Compute Preemption in GP100, applications can run as long as needed while scheduled alongside other tasks.
Atomics
Kepler implements shared memory atomics using a lock/update/unlock pattern that could be expensive. Maxwell improved atomic operations by implementing native hardware support for shared memory atomic operations for 32-bit integers, and native shared memory 32-bit and 64-bit compare-and-swap (CAS). Pascal improves atomic operations using Unified Memory and NVLink. The atomicAdd() function can apply to 32 and 64-bit integer and floating-point data.