“TensorFlow with multiple GPUs”
TensorFlow multiple GPUs support
If a TensorFlow operation has both CPU and GPU implementations, TensorFlow will automatically place the operation to run on a GPU device first. If you have more than one GPU, the GPU with the lowest ID will be selected by default. However, TensorFlow does not place operations into multiple GPUs automatically. To override the device placement to use multiple GPUs, we manually specify the device that a computation node should run on.
GPU placement
Let’s start with a simple example to place all operations into a specific GPU manually.
import tensorflow as tf
with tf.device('/gpu:0'): # Run nodes with GPU 0
m1 = tf.constant([[3, 5]])
m2 = tf.constant([[2],[4]])
product = tf.matmul(m1, m2)
sess = tf.Session()
print(sess.run(product))
sess.close()
To verify the operation’s device placement, we set log_device_placement to True to log the information:
import tensorflow as tf
# Construct 2 op nodes (m1, m2) representing 2 matrix.
m1 = tf.constant([[3, 5]])
m2 = tf.constant([[2],[4]])
product = tf.matmul(m1, m2) # A matrix multiplication op node
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(product))
sess.close()
# MatMul: (MatMul): /job:localhost/replica:0/task:0/cpu:0
# Const_1: (Const): /job:localhost/replica:0/task:0/cpu:0
# Const: (Const): /job:localhost/replica:0/task:0/cpu:0
Multiple GPUs
The code below allows operations to run on multiple GPUs. We use 3 GPUs to compute 3 separate matrix multiplication. Each multiplication generates a 2x2 matrix. Then we use a CPU to perform an element-wise sum over the matrices.
import tensorflow as tf
c = []
for i, d in enumerate(['/gpu:0', '/gpu:1', '/gpu:2']):
with tf.device(d):
a = tf.get_variable(f"a_{i}", [2, 3], initializer=tf.random_uniform_initializer(-1, 1))
b = tf.get_variable(f"b_{i}", [3, 2], initializer=tf.random_uniform_initializer(-1, 1))
c.append(tf.matmul(a, b))
with tf.device('/cpu:0'):
sum = tf.add_n(c)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
init = tf.global_variables_initializer()
sess.run(init)
print(sess.run(sum))
# [[-0.36499196 -0.07454088]
# [-0.33966339 0.30250686]]
Soft placement
However, we want to use the same code to run on machines without GPUs or with fewer GPUs. To handle multiple devices configuration, set allow_soft_placement to True. It places the operation into an alternative device automatically. Otherwise, the operation will throw an exception if the device does not exist.
sess = tf.Session(config=tf.ConfigProto(
allow_soft_placement=True, log_device_placement=True))
Without the soft placement, it will throw an error:
InvalidArgumentError (see above for traceback): Cannot assign a device for operation 'b_1': Operation was explicitly assigned to /device:GPU:1 but available devices are [ /job:localhost/replica:0/task:0/device:CPU:0 ]. Make sure the device specification refers to a valid device.
[[Node: b_1 = VariableV2[_class=["loc:@b_1"], container="", dtype=DT_FLOAT, shape=[3,2], shared_name="", _device="/device:GPU:1"]()]]
Parallelism
There are two types of parallelism:
- Model parallelism - Different GPUs run different part of the code. Batches of data pass through all GPUs.
- Data parallelism - We use multiple GPUs to run the same TensorFlow code. Each GPU is feed with different batch of data.
If a host have multiple GPUs with the same memory and computation capacity, it will be simpler to scale with data parallelism.
Model parallelism
GPU 0 is responsbile for the matrix multiplication and GPU 1 is responsible for the addition.
import tensorflow as tf
c = []
a = tf.get_variable(f"a", [2, 2], initializer=tf.random_uniform_initializer(-1, 1))
b = tf.get_variable(f"b", [2, 2], initializer=tf.random_uniform_initializer(-1, 1))
with tf.device('/gpu:0'):
c.append(tf.matmul(a, b))
with tf.device('/gpu:1'):
c.append(a + b)
with tf.device('/cpu:0'):
sum = tf.add_n(c)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True, allow_soft_placement=True))
init = tf.global_variables_initializer()
sess.run(init)
print(sess.run(sum))
# [[ 0.80134761 1.43282831]
# [-1.69707346 -0.5467118 ]]
Data parallelism
We run multiple copies of the model (called towers). Each tower is assigned to a GPU. Each GPU is responsible for a batch of data.
import tensorflow as tf
c = []
a = tf.get_variable(f"a", [2, 2, 3], initializer=tf.random_uniform_initializer(-1, 1))
b = tf.get_variable(f"b", [2, 3, 2], initializer=tf.random_uniform_initializer(-1, 1))
# Multiple towers
for i, d in enumerate(['/gpu:0', '/gpu:1']):
with tf.device(d):
c.append(tf.matmul(a[i], b[i])) # Tower i is responsible for batch data i.
with tf.device('/cpu:0'):
sum = tf.add_n(c)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True, allow_soft_placement=True))
init = tf.global_variables_initializer()
sess.run(init)
print(sess.run(sum))
GPU memory
By default, TensorFlow requests nearly all of the GPU memory of all GPUs to avoid memory fragmentation (since GPU has much less memory, it is more vulnerable to fragmentation). This may not be desirable if other processes are running on other GPUs.
TensorFlow can grow its memory gradually by (if desired):
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config, ...)
Or to specify that we want say 40% of the total GPUs memory.
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
session = tf.Session(config=config, ...)
Placing Variables on CPU
If all GPU cards have the same computation and memory capacity, we can scale the solution by using multiple towers each handle different batches of data. If the data transfer rate between GPUs are relative slow, we pin the model parameters onto the CPU. Otherwise, we places the variables equally across GPUs. The final choice depends on the model, hardware and the hardware configurations. Usually, the design is chosen by benchmarking. In the diagram below, we pin the parameters onto the CPU.
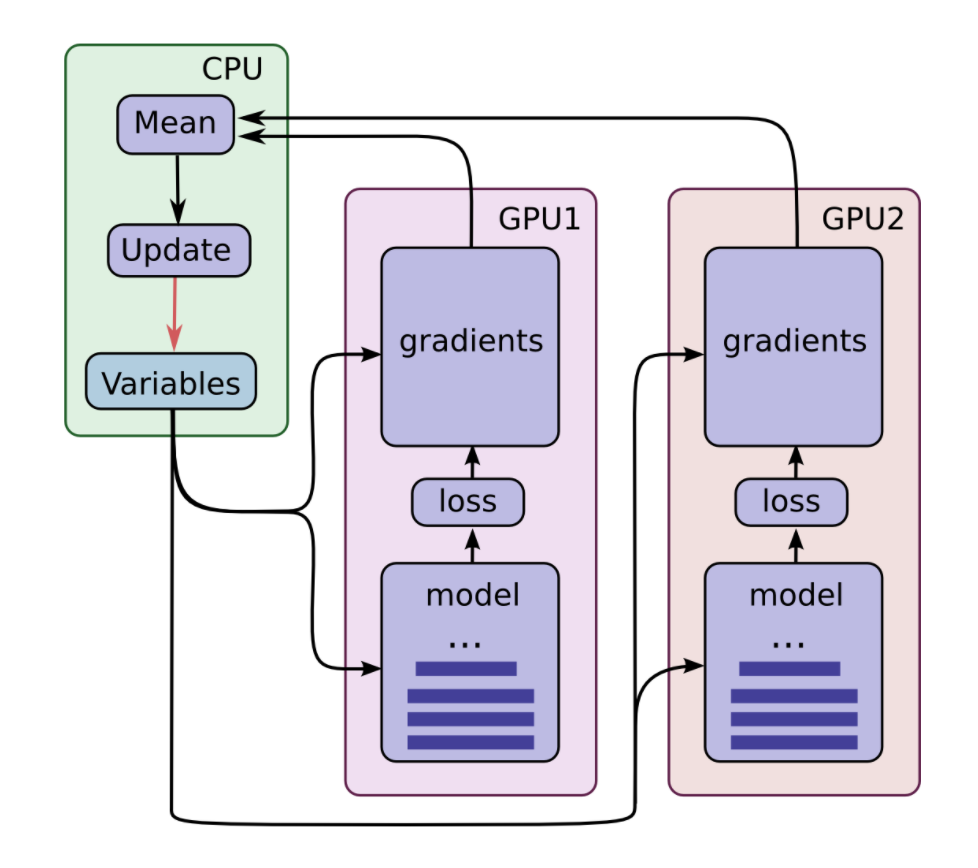
Each GPU computes predictions and gradients for a specific batch of data. This setup divides a larger batch of data across the GPUs. Model parameters are pined onto the CPU. The CPU waits for all GPU gradient computations, and the averaged the result. Then CPU computes the new model parameters and updates all GPUs.
The code below:
- Build a CIFAR-10 model with parameters shared by all towers.
- Compute the loss for a single tower.
def tower_loss(scope):
# Build the CIFAR-10 data, model and loss.
images, labels = cifar10.distorted_inputs()
logits = cifar10.inference(images) # The model is build without the tower scope.
_ = cifar10.loss(logits, labels)
# Assemble all of the losses for the current tower only.
losses = tf.get_collection('losses', scope)
# Calculate the total loss for the current tower.
total_loss = tf.add_n(losses, name='total_loss')
loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')
loss_averages_op = loss_averages.apply(losses + [total_loss])
with tf.control_dependencies([loss_averages_op]):
total_loss = tf.identity(total_loss)
return total_loss
In cifar10.inference, all variables are instantiate using tf.get_variable without the tower scope. Hence all model parameters are shared among towers.
def inference(images):
"""Build the CIFAR-10 model.
"""
# conv1
with tf.variable_scope('conv1') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 3, 64],
stddev=1e-4, wd=0.0)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv1)
Also all variables are created with _variable_on_cpu which pins the variables onto the CPU 0.
def _variable_on_cpu(name, shape, initializer):
"""Helper to create a Variable stored on CPU memory.
"""
with tf.device('/cpu:0'):
var = tf.get_variable(name, shape, initializer=initializer)
return var
To train the model with multiple GPUs, we assign the operations to specific GPUs.
tower_grads = []
for i in xrange(FLAGS.num_gpus):
with tf.device('/gpu:%d' % i):
with tf.name_scope('%s_%d' % (cifar10.TOWER_NAME, i)) as scope:
# Calculate the loss for one tower of the CIFAR model. This function
# constructs the entire CIFAR model but shares the variables across
# all towers.
loss = tower_loss(scope)
# Reuse variables for the next tower.
tf.get_variable_scope().reuse_variables()
# Retain the summaries from the final tower.
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
# Calculate the gradients for the batch of data on this CIFAR tower.
grads = opt.compute_gradients(loss)
# Keep track of the gradients across all towers.
tower_grads.append(grads)
# We must calculate the mean of each gradient.
# Note that this is the synchronization point across all towers.
# It takes tower_grads as a parameter. It waits until all GPUs are finished.
grads = average_gradients(tower_grads)
We use name scope to retrive the loss for a specific tower:
with tf.name_scope('%s_%d' % (cifar10.TOWER_NAME, i)) as scope:
loss = tower_loss(scope)
def tower_loss(scope):
...
losses = tf.get_collection('losses', scope)
...
Loss function:
def loss(logits, labels):
labels = tf.cast(labels, tf.int64)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name='cross_entropy_per_example')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'), name='total_loss')
The source code is avaiable here. below:
Placement decisions
How to handle variable placement (on CPU or equally shared in GPUs) depends on the model, hardware, and the hardware configuration. For example, for two systems built with NVIDIA Tesla P100s but one using PCIe and the other NVLink may have different recommendations. Below is some recommendations from the TensorFlow’s documentation:
-
Tesla K80: If the GPUs are on the same PCI Express and are able to communicate using NVIDIA GPUDirect Peer to Peer, we place the variables equally across the GPUs. Otherwise, we place the variables on the CPU.
-
Titan X, P100: For models like ResNet and InceptionV3, placing variables on the CPU. But for models with a lot of variables like AlexNet and VGG, using GPUs with NCCL is better.
Place variables on GPU devices
We can place variables on GPU devices similar to CPU. The major difference is that we may have 1 CPU but many GPUs. So we may manually rotate the GPU assignment:
def _variable_on_gpu(name, shape, initializer, id):
with tf.device(f"/cpu:{id}"):
var = tf.get_variable(name, shape, initializer=initializer)
return var
As an advance topic, we discuss how to place operations including variables onto the least busy GPU.
tf.device calls the device_setter for each Op that is created and it returns the least busy device to place the op.
def _resnet_model_fn():
# Loops over the number of GPUs and creates a copy ("tower") of the model on each GPU.
for i in range(num_gpus):
worker = '/gpu:%d' % i
# Determine the least busy GPU
device_setter = _create_device_setter(is_cpu_ps, worker, FLAGS.num_gpus)
# Creates variables on the first loop.
# On subsequent loops reuse is set to True,
# which results in the "towers" sharing variables.
with tf.variable_scope('resnet', reuse=bool(i != 0)):
with tf.name_scope('tower_%d' % i) as name_scope:
# tf.device calls the device_setter for each Op that is created.
# device_setter returns the device the Op is to be placed on.
with tf.device(device_setter):
# Creates the "tower".
_tower_fn(is_training, weight_decay, tower_features[i],
tower_labels[i], tower_losses, tower_gradvars,
tower_preds, False)
_create_device_setter returns the device the Op is to be placed on:
def _create_device_setter(is_cpu_ps, worker, num_gpus):
"""Create device setter object."""
gpus = ['/gpu:%d' % i for i in range(num_gpus)]
return ParamServerDeviceSetter(worker, gpus)
To determine the device:
class GpuParamServerDeviceSetter(object):
"""Used with tf.device() to place variables on the least loaded GPU.
A common use for this class is to pass a list of GPU devices, e.g. ['gpu:0',
'gpu:1','gpu:2'], as ps_devices. When each variable is placed, it will be
placed on the least loaded gpu. All other Ops, which will be the computation
Ops, will be placed on the worker_device.
"""
def __init__(self, worker_device, ps_devices):
"""Initializer for GpuParamServerDeviceSetter.
Args:
worker_device: the device to use for computation Ops.
ps_devices: a list of devices to use for Variable Ops. Each variable is
assigned to the least loaded device.
"""
self.ps_devices = ps_devices
self.worker_device = worker_device
self.ps_sizes = [0] * len(self.ps_devices)
def __call__(self, op):
if op.device:
return op.device
if op.type not in ['Variable', 'VariableV2', 'VarHandleOp']:
return self.worker_device
# Gets the least loaded ps_device
device_index, _ = min(enumerate(self.ps_sizes), key=operator.itemgetter(1))
device_name = self.ps_devices[device_index]
var_size = op.outputs[0].get_shape().num_elements()
self.ps_sizes[device_index] += var_size
return device_name
Building the tower:
def _tower_fn(is_training, weight_decay, feature, label, data_format,
num_layers, batch_norm_decay, batch_norm_epsilon):
"""Build computation tower (Resnet).
"""
model = cifar10_model.ResNetCifar10(
num_layers,
batch_norm_decay=batch_norm_decay,
batch_norm_epsilon=batch_norm_epsilon,
is_training=is_training,
data_format=data_format)
logits = model.forward_pass(feature, input_data_format='channels_last')
tower_pred = {
'classes': tf.argmax(input=logits, axis=1),
'probabilities': tf.nn.softmax(logits)
}
tower_loss = tf.losses.sparse_softmax_cross_entropy(
logits=logits, labels=label)
tower_loss = tf.reduce_mean(tower_loss)
model_params = tf.trainable_variables()
tower_loss += weight_decay * tf.add_n(
[tf.nn.l2_loss(v) for v in model_params])
tower_grad = tf.gradients(tower_loss, model_params)
return tower_loss, zip(tower_grad, model_params), tower_pred
Variable Distribution and Gradient Aggregation
More advanced technique using parameter server can be found here.